
Сведение рук в тренажере: придай форму своим грудным! | willandwin.ru
Сведение рук в тренажере, это изолированные упражнение, направленное на развитие грудных мышц. Главным отличием от остальных, является возможность развить среднюю часть груди. Называют тренажер для свидания по-разному: бабочка, баттерфляй или Пек дек(peck deck). Существует несколько вариантов данного упражнения. Обо всем этом мы с вами поговорим далее. Я постараюсь подробно объяснить в чем между ними отличие. А вы уже сами попробуете их и решите какой из вариантов вы будете выполнять. Ну или ваш выбор будет зависеть от того, какой именно тренажер есть у вас в зале. Надо только понимать, что это упражнение не поможет вам нарастить мышечную массу. Зато отлично подойдет тем атлетам, которые хотят придать выразительная форму своим грудным. Но обо всем по порядку.
Какие мышцы работают в сведение рук в тренажере?
Хоть сведение рук в тренажере и является изолированным, все равно оно задействует достаточное количество основных и второстепенных мышц.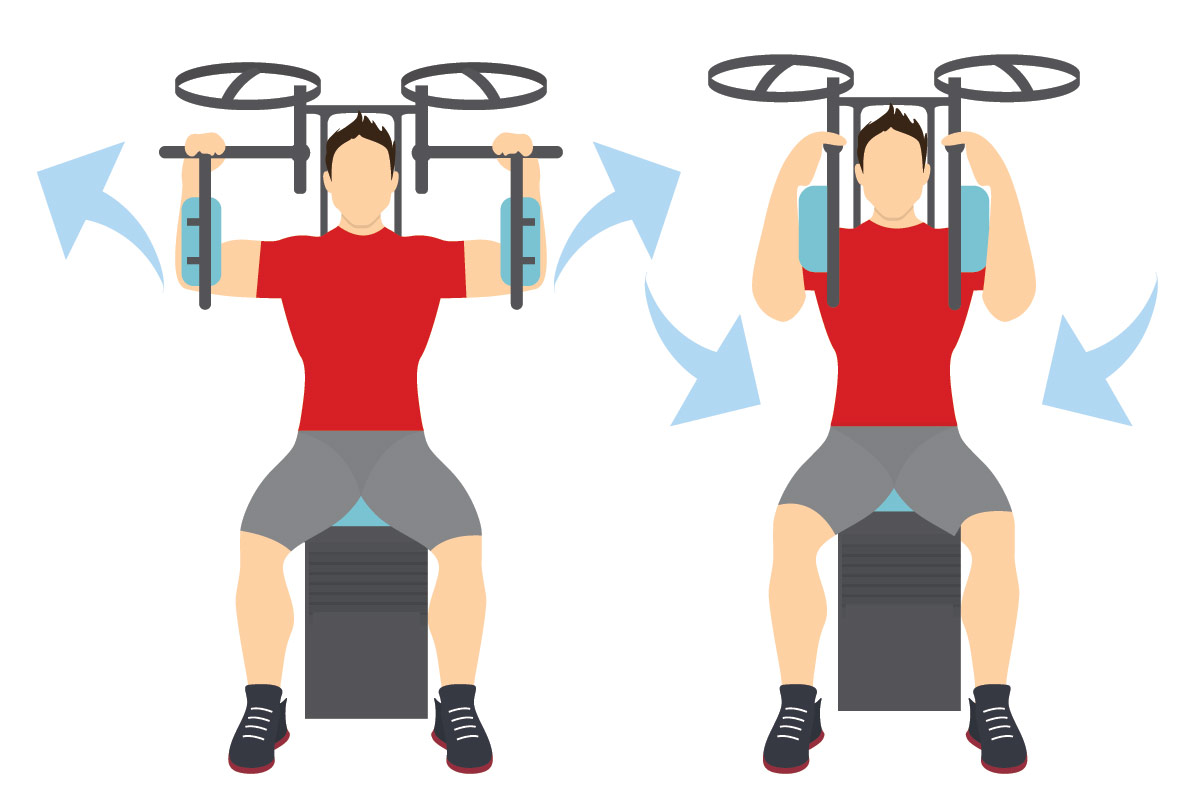 Пусть большинство из них и не участвует в самом движении, а работает лишь в статике. Все равно они получают определенную долю нагрузки.
Пусть большинство из них и не участвует в самом движении, а работает лишь в статике. Все равно они получают определенную долю нагрузки.
К основным мышцами относятся:
- Большая грудная
- Малая грудная
Именно для их формирования мы выполняем сведение в тренажере. Они отвечают за приведение плечей друг к другу. Не путайте с дельтовидными мышцами. Большая и малая грудные, крепятся к плечевой кости. То есть более простыми словами, сводят наши руки друг с другом.
- Передний пучок дельты. Наша главная задача сделать так, чтобы эта мышца не стала доминировать и не забрала всю нагрузку на себя. Как это сделать я расскажу чуть позже.
Больше о мышцах груды вы можете узнать из статьи «АНАТОМИЯ ГРУДНЫХ МЫШЦ«
Сведение рук в тренажБолереПлюсы и минусы данного упражненияВ отличие от других упражнений на грудь, сведение рук в тренажере имеет множество плюсов.
- При сведении не теряется нагрузка верхней точке. То есть когда мы сводим руки в месте, наши грудные мышцы напрягаются еще сильнее. Все потому что на них действует сила противодействия самого тренажера. Который пытается развести ваши руки в стороны. Чтобы этого не случилось, нам приходится держать грудные в постоянном напряжении.
- Подходит для атлетов с любым уровнем подготовки. Тренажеры были специально придуманы для того, чтобы нам было проще выполнять тяжелые упражнения. Поэтому сведение рук могут делать как новички, так и профессионалы.
- Отсутствует работа жимовых мышц. Так как мы не выжимаем отягощение, а пытаемся свести руки вместе. Мы исключаем из работы такие мышцы как трицепс, зубчатые мышцы и дельты.
- Возможность прокачать среднюю часть грудных. Это одно из немногих упражнений, которое позволяет прочувствовать эту область.
- Меньший шанс травматизма. Все из-за отсутствия вертикальный нагрузки на локтевой сустав.
 То есть вес отягощением не давит на него сверху.
То есть вес отягощением не давит на него сверху.
Как вы видите, упражнение по праву достойно быть в вашей тренировочной программе. Хотя в нем есть несколько минусов.
- Отсутствие роста массы. Выполняя сведение, вряд ли получится увеличить мышечную массу грудных. Поэтому мы можем рассчитывать только на улучшение их формы.
- Меньшее включение мышц стабилизаторов. В отличие от разведения рук лежа, где в работе участвуют множество мышц стабилизаторов. Сведение нагружает только грудные мышцы. Поэтому мы не сможем проработать более мелкие мышцы.
Конечно данные минусы не являются критическими. Тем более культуристы, которые используют это упражнение в тренировках их знают. Но для них плюсы все же перевешивают и являются более приоритетными.
Разновидности тренажеров
Залы за долгие годы сильно изменились. Раньше практически не было тренажеров. Но сейчас их большое множество. Для сведения рук их существует два варианта.
Тренажер Пек-дек с упором руками
Тренажер очень популярен. Для того чтобы в нем выполнять сведения рук. Надо его отрегулировать под свой рост, прежде чем приступать к выполнению упражнения. Основными критериями тут является высота сидения. Мы должны подобрать такую, чтобы руки сводились перед грудью. А также имеется возможность взяться рукой чуть выше или ниже. Это поможет сместить акцент на грудные. То есть, если мы возьмемся чуть выше, тогда нагрузку получит больше верхняя часть. Если ниже, то нижняя. Но надо понимать, что эти изменения не столь значительные. Поэтому лучше всего браться посередине и задействовать всю грудную область.
Тренажер Пек-дек с упором предплечьем
Этот еще один тренажер в котором можно делать сведение рук. Я его помню еще с юношеских пор, но тогда он мне казался мало эффективными. Если бы я знал, то что знаю сейчас, мое мнение было бы совсем другим. Данный тренажер позволяет проработать грудные мышцы с максимальной амплитудой. Это позволит нам ее сильнее растянуть, задействовав большое число мышечных волокон. А за счет фиксации предплечья в мягкие подкладки, полностью пропадает нагрузка с локтевых суставов. Высота тренажера устанавливается аналогично прошлому. Только теперь ориентиром для нас выступают локти. В классическом варианте, они должны сходиться друг с другом перед грудью.
Это позволит нам ее сильнее растянуть, задействовав большое число мышечных волокон. А за счет фиксации предплечья в мягкие подкладки, полностью пропадает нагрузка с локтевых суставов. Высота тренажера устанавливается аналогично прошлому. Только теперь ориентиром для нас выступают локти. В классическом варианте, они должны сходиться друг с другом перед грудью.
Техника выполнения
Перед тем как начать упражнение, повторим моменты про настройку тренажера. Без этого мы не сможем добиться идеальной техники.
Исходное положение:
- Подойдите к тренажеру Пек-дек. Установите нужный вес. Для этого нужно вставить специальный ограничитель в отверстие, с нужным нам числом блоков.
- Отрегулируйте высоту сиденья, так чтобы ваши руки сводились в центре грудных. А предплечье находилось на одном уровне с дельтами. Локти должны смотреть в стороны. Если у вас тренажер с упорами для предплечий. Тогда ориентируйтесь по положению локтей. И смотреть они уже будут не в стороны, а вниз.

- Разверните тело в одну из сторон и возьмите за рукоятку (либо упритесь предплечьями в специальные подкладки). Приведите ее к центру. Далее, разверните тело в другую сторону и возьмите вторую рукоять и сведите их вместе. Именно с этого положения мы будем начинать движение.
- Лопатки должны быть сведены и прижать к спинке тренажера. Грудь немного выставлена вперед. В пояснице небольшой прогиб, спина прямая. Взгляд направлен вперед.
- Стопы плотно прижаты к полу. От этого зависит устойчивость нашего тела. Если же из-за небольшого роста, ваши ноги не достают до пола, тогда вы можете подложить под них блины либо степ-платформы.
Выполнение:
- На вдохе разведите руки в стороны, на максимальное расстояние друг от друга.
- Потом мощным движением на выдохе сведите руки друг к другу и немного распрямите локти. Это позволит как можно сильнее нагрузить грудные мышцы. Выполняя вариант с упором предплечий, старайтесь вести локти как можно ближе друг к другу.
 Так вам проще будет задействовать грудные и фокусироваться на их работе.
Так вам проще будет задействовать грудные и фокусироваться на их работе. - В конечной точке, максимально напрягите грудь и задержитесь ненадолго в этом положении.
- Повторите заданное количество раз.
Рекомендации по выполнению
Для того чтобы добиться большего результата есть некоторые рекомендации, которые помогут вам в этом.
- Важно исключить из работы дельты. Для этого контролируйте положение плечей. Исключите любую возможность их подъема вверх. А не то они заберут всю нагрузку на себя, а часть уйдет трапеции.
- Не наклоняйтесь во время сведения. При наклоне корпуса нагрузка также смещается на передние дельты. И возрастает шанс их травматизма.
- Не отрывайте таз. Если это происходит, значит вы взяли слишком большой вес. Стоит его снизить.
- Напрягите мышцы пресса. Это очень важно, так вы сможете более жестко зафиксировать свое тело.
- Не заводите руки слишком далеко. Разведение должно быть комфортным для ваших грудных и плечей.
Если же вы чувствуете боль значит вы слишком далеко завели руки.
- Не бойтесь выпрямлять локти в момент сведения. Как я уже говорил ранее, риск травмировать локти в данном упражнении минимален. Конечно движение должно быть подконтрольным. Если у вас не получается контролировать этот момент, тогда воздержитесь от данного движения.
- Фокусируется свое внимание на грудных. Вы должны чувствовать работу грудных мышц как в положительной фазе во время сведения. Так и в отрицательной в момент разведения.
- Не сгибайте кисть. Если не получается держать кисти ровными, значит ваши суставы и связки еще слабые. Поэтому снизьте вес. И как почувствуете, что ваши суставы окрепли, увеличьте его.
Есть еще один вариант выполнения сведения рук в тренажере. Увидеть его можно достаточно редко, но все равно порою такая техника практикуется. Речь идет о сведение каждой руки по отдельности. Такой вариант помогает уменьшить дисбаланс в развитии правой и левой части грудных. Сейчас односторонний тренинг набирает обороты. И даже появились атлеты, которые его пропагандируют. Но вернемся к нашему упражнению. В данном варианте, мы сможем работать по максимальной амплитуде. Ведь нам не мешает другая рука, поэтому рукоять тренажера мы можем заводить дальше от центра. Для новичков это будет хорошее упражнение, которое поможет почувствовать работу грудных мышц. Ведь на одной части проще фокусировать свое внимание, чем на двух. Да и вообще, я всем советую попробовать такой вариант сведений. Ваши мышцы испытают новый стресс. А это для нас только на руку.
Сейчас односторонний тренинг набирает обороты. И даже появились атлеты, которые его пропагандируют. Но вернемся к нашему упражнению. В данном варианте, мы сможем работать по максимальной амплитуде. Ведь нам не мешает другая рука, поэтому рукоять тренажера мы можем заводить дальше от центра. Для новичков это будет хорошее упражнение, которое поможет почувствовать работу грудных мышц. Ведь на одной части проще фокусировать свое внимание, чем на двух. Да и вообще, я всем советую попробовать такой вариант сведений. Ваши мышцы испытают новый стресс. А это для нас только на руку.
Всем успехов в тренировках!
Сведение рук в тренажере (Бабочка)
6 минут на освоение. 345 просмотров
AtletIQ — приложение для бодибилдинга
600 упражнений, более 100 программ тренировок на массу, силу, рельеф для дома и тренажерного зала. Это фитнес-револиция!
Общая информация
Тип усилия
ДругоеЖимНетСтатическиеТяга
Вид упражнения
СиловоеРастяжкаКардиоПлиометрическоеStrongmanКроссфитПауэрлифтингТяжелая атлетикаСтрейчингово-силовое упражнениеЙогаДыханиеКалланетика
Тип упражнения
БазовоеИзолирующееНет
Сложность
НачинающийПрофессионалСредний
Целевые мышцы
Сведение рук в тренажере (Бабочка) видео
Как делать упражнение
- Сядьте на тренажер с плоской спинкой.
- Возьмитесь за ручки тренажера. Это исходная позиция. Совет: отрегулируйте тренажер таким образом, чтобы во время выполнения упражнения ваши плечи оказались параллельны полу.
- Медленно сведите ручки тренажера друг к другу, почувствуйте напряжение в середине груди.
- Выдохните и секунду удерживайте напряжение.
- На вдохе вернитесь в исходную позицию – мышцы груди должны полностью растянуться.
- Повторите упражнение рекомендуемое количество раз.
Вариации: это упражнение можно выполнять с использованием тросов. А можно немного иначе расположить руки: под прямым углом упереться ими в подставки, а затем свести локти вместе.
Фото с правильной техникой выполнения
Какие мышцы работают?
При соблюдении правильной техники выполнения упражнения «Сведение рук в тренажере (Бабочка)» работают следующие группы мышц: Грудь, а также задействуются вспомогательные мышцы:
Вес и количество повторений
Количество повторений и рабочий вес зависит от вашей цели и других параметров. Но общие рекомендации могут быть представлены в виде таблицы:
Но общие рекомендации могут быть представлены в виде таблицы:
| Цель | Подходы | Повторений | Вес, %1Rm | Отдых м/у подходами |
|---|---|---|---|---|
| Развитие силы | 2-6 | 1-5 раз | 100-85% | 3-7 мин |
| Набор массы | 3-6 | 6-12 раз | 85-60% | 1-4 мин |
| Сушка, рельеф | 2-4 | 13-25 раз | 60-40% | 1-2 мин |
Сделать тренинг разнообразнее и эффективнее можно, если на каждой тренировке изменять количество повторений и вес снаряда. Важно при этом не выходить за определенные значения!
*Укажите вес снаряда и максимальное количество повторений, которое можете выполнить с этим весом.
Не хотите считать вручную? Установите приложение AtletIQ!
- Электронный дневник тренировок
- Помнит ваши рабочие веса
- Считает нагрузку под вас
- Контролирует время отдыха
Лучшие программы тренировок с этим упражнением
Среди программ тренировок, в которых используется упражнение «Сведение рук в тренажере (Бабочка)» одними из лучших по оценкам спортсменов являются эти программы:
Чем заменить?
Вы можете попробовать заменить упражнение «Сведение рук в тренажере (Бабочка)» одним из этих упражнений. Возможность замены определяется на основе задействуемых групп мышц.
Возможность замены определяется на основе задействуемых групп мышц.Сведение рук в тренажере (Бабочка) Author: AtletIQ: on Сведение рук в тренажере (Бабочка) — польза упражнения, как правильно выполнять и сколько подходов делать.. Rating: 5
Разведение рук в тренажере peck-deck. Все тонкости и секреты!
Какие мышцы работают в сведение рук в тренажере?
Хоть сведение рук в тренажере и является изолированным, все равно оно задействует достаточное количество основных и второстепенных мышц. Пусть большинство из них и не участвует в самом движении, а работает лишь в статике. Все равно они получают определенную долю нагрузки.
К основным мышцами относятся
:
- Большая грудная
- Малая грудная
Именно для их формирования мы выполняем сведение в тренажере. Они отвечают за приведение плечей друг к другу. Не путайте с дельтовидными мышцами. Большая и малая грудные, крепятся к плечевой кости. То есть более простыми словами, сводят наши руки друг с другом.
Не путайте с дельтовидными мышцами. Большая и малая грудные, крепятся к плечевой кости. То есть более простыми словами, сводят наши руки друг с другом.
- Передний пучок дельты. Наша главная задача сделать так, чтобы эта мышца не стала доминировать и не забрала всю нагрузку на себя. Как это сделать я расскажу чуть позже.
Сведение рук в тренажере
Мышцы ассистенты:
- Клювовидно-плечевая мышца. Участвует в подъеме плеча вверх.
- Передняя зубчатая мышца. Это мышцы, которые крепятся к грудной клетке и активно работают при ее расширении и сужении.
- Ромбовидные мышцы.
Отвечают за сведение лопаток.
Мышцы стабилизаторы:
- Прямая мышца живота
- Выпрямители позвоночника
Эти мышцы помогают сохранять ровное положение тела.
Полезные советы
- Делая сведение рук в тренажере «бабочка», очень важно хорошо вдавливать плечи в мягкую спинку.
 При этом лопатки должны сводиться вместе, но ни в коем случае они не должны отрываться, так как нагрузка с груди переходит на спину, и упражнение становится менее эффективным.
При этом лопатки должны сводиться вместе, но ни в коем случае они не должны отрываться, так как нагрузка с груди переходит на спину, и упражнение становится менее эффективным. - Делая сведение, необходимо держать локти развернутыми в разные стороны, а не вниз. Во время непосредственного сведения следует выпрямлять локти, чтобы мышцы груди лучше сократились. Когда руки будут разводиться, то локти рекомендуется немного согнуть.
- Высота сидения у тренажера должна быть такой, чтобы его рукояти находились напротив груди. Допустимое смещение вверх и вниз составляет всего 10 см. Если оно будет большим, то в работу включится исключительно нижняя или верхняя часть груди.
- Слишком сильно разводить руки не стоит, так как оптимальным вариантом считается положение, когда кисти доходят до плоскости груди или находятся немного впереди.
Упражнение нужно выполнять после завершения двух базовых, иначе оно не будет иметь должную эффективность.
Плюсы и минусы данного упражнения
В отличие от других упражнений на грудь, сведение рук в тренажере имеет множество плюсов.
- При сведении не теряется нагрузка верхней точке. То есть когда мы сводим руки в месте, наши грудные мышцы напрягаются еще сильнее. Все потому что на них действует сила противодействия самого тренажера. Который пытается развести ваши руки в стороны. Чтобы этого не случилось, нам приходится держать грудные в постоянном напряжении.
- Подходит для атлетов с любым уровнем подготовки. Тренажеры были специально придуманы для того, чтобы нам было проще выполнять тяжелые упражнения. Поэтому сведение рук могут делать как новички, так и профессионалы.
- Отсутствует работа жимовых мышц. Так как мы не выжимаем отягощение, а пытаемся свести руки вместе. Мы исключаем из работы такие мышцы как трицепс, зубчатые мышцы и дельты.
- Возможность прокачать среднюю часть грудных. Это одно из немногих упражнений, которое позволяет прочувствовать эту область.
- Меньший шанс травматизма. Все из-за отсутствия вертикальный нагрузки на локтевой сустав. То есть вес отягощением не давит на него сверху.
Как вы видите, упражнение по праву достойно быть в вашей тренировочной программе. Хотя в нем есть несколько минусов.
- Отсутствие роста массы. Выполняя сведение, вряд ли получится увеличить мышечную массу грудных. Поэтому мы можем рассчитывать только на улучшение их формы.
- Меньшее включение мышц стабилизаторов. В отличие от разведения рук лежа, где в работе участвуют множество мышц стабилизаторов. Сведение нагружает только грудные мышцы. Поэтому мы не сможем проработать более мелкие мышцы.
Плюсы и минусы данного упражнения
Конечно данные минусы не являются критическими. Тем более культуристы, которые используют это упражнение в тренировках их знают. Но для них плюсы все же перевешивают и являются более приоритетными.
Разбор упражнения
Анатомия
- Основной движитель – большие и малые грудные мышцы.
 За счет их сокращения происходит приведение плеча к центру тела, при разведении мышцы компенсируют инерционное усилие, и делают работу плавной.
За счет их сокращения происходит приведение плеча к центру тела, при разведении мышцы компенсируют инерционное усилие, и делают работу плавной. - Дополнительные работающие мышцы – это передняя дельтовидная, передняя зубчатая, клювовидно-плечевая мышца, верхняя головка бицепса.
- Мышцы- стабилизаторы – широчайшие мышцы спины, ромбовидная, длинная мышца спины, прямая мышца пресса, квадрицепс и бицепс бедра, ягодичные.
Плюсы упражнения
- Возможность работать на любом уровне физического развития. Упражнение доступно и опытным бодибилдерам, и новичкам с первого дня занятий;
- Движение дает меньшую нагрузку на стабилизаторы плеча, чем сведение гантелей перед грудью. Это позволяет включать его в реабилитационные программы после травмы плеч;
- Нагрузка плавно распределяется между всеми пучками грудных мышц, и позволяет качественно их проработать;
- Отсутствует работа жимовых мышц – трицепса, и спины. Можно тренировать грудь в изоляции
Минусы упражнения
- Построить массу мышц одними «разводками» не получилось пока ни у кого.
 Это движение нужно как дополнение к жимам, а не как их замена;
Это движение нужно как дополнение к жимам, а не как их замена; - В упражнении не работают грудные мышцы, а вот стабилизаторы плеча отключаются. Если включать инерцию, травму все же можно получить
Разновидности тренажеров
Залы за долгие годы сильно изменились. Раньше практически не было тренажеров. Но сейчас их большое множество. Для сведения рук их существует два варианта.
Тренажер Пек-дек с упором руками
Тренажер очень популярен. Для того чтобы в нем выполнять сведения рук. Надо его отрегулировать под свой рост, прежде чем приступать к выполнению упражнения. Основными критериями тут является высота сидения. Мы должны подобрать такую, чтобы руки сводились перед грудью. А также имеется возможность взяться рукой чуть выше или ниже. Это поможет сместить акцент на грудные. То есть, если мы возьмемся чуть выше, тогда нагрузку получит больше верхняя часть. Если ниже, то нижняя. Но надо понимать, что эти изменения не столь значительные. Поэтому лучше всего браться посередине и задействовать всю грудную область.
Тренажер Пек-дек с упором предплечьем
Этот еще один тренажер в котором можно делать сведение рук. Я его помню еще с юношеских пор, но тогда он мне казался мало эффективными. Если бы я знал, то что знаю сейчас, мое мнение было бы совсем другим. Данный тренажер позволяет проработать грудные мышцы с максимальной амплитудой. Это позволит нам ее сильнее растянуть, задействовав большое число мышечных волокон. А за счет фиксации предплечья в мягкие подкладки, полностью пропадает нагрузка с локтевых суставов. Высота тренажера устанавливается аналогично прошлому. Только теперь ориентиром для нас выступают локти. В классическом варианте, они должны сходиться друг с другом перед грудью.
Что это за тренажер?
Спорт является неотъемлемой частью нашей жизни. Благодаря ему мы можем добиться красивого и подтянутого тела, обрести уверенность в себе. В тренажерном зале есть множество возможностей для этого. В тренировки своих клиентов я включаю многофункциональный тренажер «баттерфляй». На нем можно выполнять упражнения с разными амплитудами, прорабатывать заднюю часть дельты и большую грудную мышцу, привести свое тело в тонус, добиться рельефа и пропорциональности. «Бабочка» равномерно формирует и развивает мышечную ткань.
На нем можно выполнять упражнения с разными амплитудами, прорабатывать заднюю часть дельты и большую грудную мышцу, привести свое тело в тонус, добиться рельефа и пропорциональности. «Бабочка» равномерно формирует и развивает мышечную ткань.
Устроен в виде сиденья со спинкой и двумя рукоятками. Регулируется по высоте скамейки и по ширине упоров для верного расположения рук. На тренажере можно имитировать упражнение разведение рук с гантелями, но получить более эффективный результат. Главное преимущество конструкции заключается в том, что при выполнении тренировки значительно уменьшается нагрузка на спину. Благодаря удобной регулировке устройство может принимать различные положения.
Техника выполнения
Перед тем как начать упражнение, повторим моменты про настройку тренажера. Без этого мы не сможем добиться идеальной техники.
Исходное положение:
- Подойдите к тренажеру Пек-дек. Установите нужный вес. Для этого нужно вставить специальный ограничитель в отверстие, с нужным нам числом блоков.

- Отрегулируйте высоту сиденья, так чтобы ваши руки сводились в центре грудных. А предплечье находилось на одном уровне с дельтами. Локти должны смотреть в стороны. Если у вас тренажер с упорами для предплечий. Тогда ориентируйтесь по положению локтей. И смотреть они уже будут не в стороны, а вниз.
- Разверните тело в одну из сторон и возьмите за рукоятку (либо упритесь предплечьями в специальные подкладки). Приведите ее к центру. Далее, разверните тело в другую сторону и возьмите вторую рукоять и сведите их вместе. Именно с этого положения мы будем начинать движение.
- Лопатки должны быть сведены и прижать к спинке тренажера. Грудь немного выставлена вперед. В пояснице небольшой прогиб, спина прямая. Взгляд направлен вперед.
- Стопы плотно прижаты к полу. От этого зависит устойчивость нашего тела. Если же из-за небольшого роста, ваши ноги не достают до пола, тогда вы можете подложить под них блины либо степ-платформы.
Выполнение:
- На вдохе разведите руки в стороны, на максимальное расстояние друг от друга.

- Потом мощным движением на выдохе сведите руки друг к другу и немного распрямите локти. Это позволит как можно сильнее нагрузить грудные мышцы. Выполняя вариант с упором предплечий, старайтесь вести локти как можно ближе друг к другу. Так вам проще будет задействовать грудные и фокусироваться на их работе.
- В конечной точке, максимально напрягите грудь и задержитесь ненадолго в этом положении.
- Повторите заданное количество раз.
Обратные разведения в тренажере Peck-Deck
В этой статье вы сможете ознакомиться с описанием правильной техники выполнения упражнения на задний пучок дельт – обратные разведения в тренажере Peck-Deck.
Техника выполнения:
- Отрегулируйте положение рукояток и высоту сиденья тренажера Peck-Deck так, чтобы в исходном положении расстояние между рукоятками равнялось ширине плеч, а руки, удерживающие рукоятки, были выпрямлены и параллельны полу.
- Примите исходное положение: грудная клетка прижата к спинке сиденья, туловище в вертикальном положении, спина слегка прогнута в пояснице, руки выпрямлены и держат рукоятки нейтральным хватом (ладони смотрят друг на друга).
 Слегка разведите рукоятки так, чтобы груз поднялся с упоров.
Слегка разведите рукоятки так, чтобы груз поднялся с упоров. - На вдохе напрягите задние дельты и мышцы спины, разведите рукоятки как можно дальше назад, локти должны оказаться за уровнем спины.
- В верхней точке упражнения, когда руки максимально отведены назад, сделайте небольшую паузу, еще сильнее напрягите задние дельты, а затем выдохните и плавно вернитесь в исходное положение.
- Достигнув нижнюю точку упражнения (рукоятки чуть шире плеч, груз на весу и не касается упоров), сделайте секундную паузу и приступайте к следующему повторению.
- Возможно, конструкция тренажера не позволит выполнять упражнение на выпрямленных руках. В этом случае допускается слегка согнуть руки в исходном положении. Главное: не сгибать и не разгибать руки во время движения, локтевой сустав должен быть зафиксирован до завершения сета.
Советы:
- Постарайтесь представить, что вы разводите не рукоятки, а локти. Такая визуализация поможет вам правильно включить мышцы и выполнять обратные разведения за счет усилия задних дельт и мышц спины, а не рук.

- Обязательно держите торс выпрямленным и неподвижным на протяжении всего сета. Это гарантия как безопасности, так и эффективности упражнения.
- Принципиально важно задерживать дыхание в фазе разведения рук. Во-первых, это позволяет развить более мощное усилие, а во-вторых, защищает поясницу от травм.
- Чтобы добиться максимального сокращения заднего пучка дельтовидных, средних трапеций и ромбовидных мышц, обязательно заводите локти за спину. Если это не удается, значит вы взяли слишком тяжелый вес или же вам следует поработать над улучшением гибкости плечевого сустава.
- Не гонитесь за тяжелыми весами. Секрет эффективности это строгое соблюдение правильной формы и техники выполнения упражнения.
Количество: 3-4 сета по 10-15 повторений. Обратные разведения — инструмент тонкой доводки формы и рельефа заднего пучка дельт, а также всех мышц верха спины. Кроме этого обратные разведения укрепляют мышцы-вращатели плеча, от силы которых напрямую зависит устойчивость плечевого сустава к нагрузкам.
Рекомендации по выполнению
Для того чтобы добиться большего результата есть некоторые рекомендации, которые помогут вам в этом.
- Важно исключить из работы дельты. Для этого контролируйте положение плечей. Исключите любую возможность их подъема вверх. А не то они заберут всю нагрузку на себя, а часть уйдет трапеции.
- Не наклоняйтесь во время сведения. При наклоне корпуса нагрузка также смещается на передние дельты. И возрастает шанс их травматизма.
- Не отрывайте таз. Если это происходит, значит вы взяли слишком большой вес. Стоит его снизить.
- Напрягите мышцы пресса. Это очень важно, так вы сможете более жестко зафиксировать свое тело.
- Не заводите руки слишком далеко. Разведение должно быть комфортным для ваших грудных и плечей. Если же вы чувствуете боль значит вы слишком далеко завели руки.
- Не бойтесь выпрямлять локти в момент сведения. Как я уже говорил ранее, риск травмировать локти в данном упражнении минимален. Конечно движение должно быть подконтрольным. Если у вас не получается контролировать этот момент, тогда воздержитесь от данного движения.
- Фокусируется свое внимание на грудных. Вы должны чувствовать работу грудных мышц как в положительной фазе во время сведения. Так и в отрицательной в момент разведения.
- Не сгибайте кисть. Если не получается держать кисти ровными, значит ваши суставы и связки еще слабые. Поэтому снизьте вес. И как почувствуете, что ваши суставы окрепли, увеличьте его.
Есть еще один вариант выполнения сведения рук в тренажере. Увидеть его можно достаточно редко, но все равно порою такая техника практикуется. Речь идет о сведение каждой руки по отдельности. Такой вариант помогает уменьшить дисбаланс в развитии правой и левой части грудных. Сейчас односторонний тренинг набирает обороты. И даже появились атлеты, которые его пропагандируют. Но вернемся к нашему упражнению. В данном варианте, мы сможем работать по максимальной амплитуде. Ведь нам не мешает другая рука, поэтому рукоять тренажера мы можем заводить дальше от центра. Для новичков это будет хорошее упражнение, которое поможет почувствовать работу грудных мышц. Ведь на одной части проще фокусировать свое внимание, чем на двух. Да и вообще, я всем советую попробовать такой вариант сведений. Ваши мышцы испытают новый стресс. А это для нас только на руку.
Типичные ошибки
Отсутствие разминки. Любые изолирующие упражнения всегда должны выполняться после хорошей разминки или после выполнения базовых упражнений на желаемую группу мышц. Без этого мышцы не будут достаточно подготовленными, поэтому желаемый эффект не будет достигнут.
Рывковые движения. Новички часто пытаются работать со слишком большим весом при помощи рывков. Действительно, большое отягощение легко выжимается таким способом, но при этом возрастает риск получить травму, а также снижается общая эффективность бабочки.
Округление спины. Часто под действием большого веса слабые грудные мышцы начинают передавать нагрузку на спину, и она округляется в области плеч или прогибается в пояснице. Чтобы этого не произошло, важно выставлять оптимальный для себя вес и плотно прижиматься к удобной спинке.
Неправильное движение руками. У многих людей левая и правая рука развиты неодинаково, поэтому возможна асинхронность в движении. Если одна рука будет тянуть за собой другую, то это приведет к неравномерному росту грудных мышц. Слабо работающая рука станет отстающей.
Силовые тренировки для похудения являются неотъемлемой и одной из самых главных частей процесса избавления от лишнего веса.
Разминка перед тренировкой является обязательной! О том, как это делается, читайте на нашем сайте.
Основные ошибки
Неправильно подобранный вес в тренажере
Это очень грубая ошибка, которую допускает большинство новичков. В стремлении добиться больших результатов в кратчайший срок. Атлеты просто не замечают, как постепенно увеличивают вес тренажера. При этом еще не достигнув должного уровня развития грудных мышц. И для того, чтобы хоть как-то выжать данный вес, они наклоняют корпус вперед. Тем самым подключая переднюю дельту. А так как анатомически данное упражнение, не предназначенное для ее развития. Мы рискуем просто на просто ее травмировать.
Рывковые движение и работа по инерции
Эта ошибка вытекает из первой. Для того чтобы свести руки с большим весом, многие прибегают к инерционным движениям. Выглядит все это следующим образом. При разведении, атлет расслабляет грудные и руки под тяжестью тренажера, резко отводит друг от друга. А потом с помощью рывка руки сводятся в исходное положение. Это очень опасная техника! Которая может травмировать плечо, локоть или вы заработаете надрыв грудной мышцы.
Сильный изгиб локтей и неправильное их положение
Положение локтей очень важная составляющая в этом упражнении. Конечно в тренажере где мы упираемся предплечьем, нас данная ошибка не коснется. Так как в данном варианте локти невозможно поставить иначе. Но вот в другом тренажере это возможно. И если сильно согнуть руки в локтевом суставе, мы просто не сможем как следует сократить грудные мышцы. А опускание их вниз, приведет к изгибу в кисти. И при большом весе, можно очень сильно травмировать данную область.
Обратные разведения в тренажере Peck-Deck
В этой статье вы сможете ознакомиться с описанием правильной техники выполнения упражнения на задний пучок дельт – обратные разведения в тренажере Peck-Deck.
Техника выполнения:
- Отрегулируйте положение рукояток и высоту сиденья тренажера Peck-Deck так, чтобы в исходном положении расстояние между рукоятками равнялось ширине плеч, а руки, удерживающие рукоятки, были выпрямлены и параллельны полу.
- Примите исходное положение: грудная клетка прижата к спинке сиденья, туловище в вертикальном положении, спина слегка прогнута в пояснице, руки выпрямлены и держат рукоятки нейтральным хватом (ладони смотрят друг на друга). Слегка разведите рукоятки так, чтобы груз поднялся с упоров.
- На вдохе напрягите задние дельты и мышцы спины, разведите рукоятки как можно дальше назад, локти должны оказаться за уровнем спины.
- В верхней точке упражнения, когда руки максимально отведены назад, сделайте небольшую паузу, еще сильнее напрягите задние дельты, а затем выдохните и плавно вернитесь в исходное положение.
- Достигнув нижнюю точку упражнения (рукоятки чуть шире плеч, груз на весу и не касается упоров), сделайте секундную паузу и приступайте к следующему повторению.
- Возможно, конструкция тренажера не позволит выполнять упражнение на выпрямленных руках. В этом случае допускается слегка согнуть руки в исходном положении. Главное: не сгибать и не разгибать руки во время движения, локтевой сустав должен быть зафиксирован до завершения сета.
Советы:
- Постарайтесь представить, что вы разводите не рукоятки, а локти. Такая визуализация поможет вам правильно включить мышцы и выполнять обратные разведения за счет усилия задних дельт и мышц спины, а не рук.
- Обязательно держите торс выпрямленным и неподвижным на протяжении всего сета. Это гарантия как безопасности, так и эффективности упражнения.
- Принципиально важно задерживать дыхание в фазе разведения рук. Во-первых, это позволяет развить более мощное усилие, а во-вторых, защищает поясницу от травм.
- Чтобы добиться максимального сокращения заднего пучка дельтовидных, средних трапеций и ромбовидных мышц, обязательно заводите локти за спину. Если это не удается, значит вы взяли слишком тяжелый вес или же вам следует поработать над улучшением гибкости плечевого сустава.
- Не гонитесь за тяжелыми весами. Секрет эффективности это строгое соблюдение правильной формы и техники выполнения упражнения.
Количество: 3-4 сета по 10-15 повторений. Обратные разведения — инструмент тонкой доводки формы и рельефа заднего пучка дельт, а также всех мышц верха спины. Кроме этого обратные разведения укрепляют мышцы-вращатели плеча, от силы которых напрямую зависит устойчивость плечевого сустава к нагрузкам.
Включение в программу
Сведения рук в тренажере может по-разному использоваться в тренировочных программах. Новичкам я бы не советовал в первые же дни своих тренировок к нему приступать. В начале потренируйте свои грудные более сложными базовыми упражнениями. Такими как: ЖИМ ШТАНГИ ЛЕЖА и ЖИМ ГАНТЕЛИ НА НАКЛОННОЙ СКАМЬЕ. А спустя 2-3 недели, можете потихоньку добавлять в тренировку сведения.
В основном большинство культуристов предпочитают делать изолированные упражнения со средним или большим количеством раз. Классическая схема 3-4 подхода из них 1 разминочный на 12-20 повторений.
Так как упражнение, изолированное то нет никакого смысла выполнять его в начале тренировки. Вы только утомите мышцы, и не сможете в базовых упражнениях показать хорошие результаты. Хотя билдеры с большим тренировочным стажем, иногда используют стратегию предварительного мышечного утомления. То есть, в начале делают сведения в тренажере, а потом более сложное упражнение. Так они пытаются сместить акцент с трицепсов на грудные мышцы. Но если вы не используете эту стратегию, тогда ставьте сведения в конце тренировки. Для того чтобы как следует добить и без того уставшие грудные.
Главное помните, что ваши движения должны быть подконтрольными. Не вес управляет вами, а вы им. Так что попридержите свое эго и постепенно поднимайтесь на вершину пьедестала. И если вы приложите хорошую дозу усилий и терпения, тогда в качестве бонуса вы получите большую и развитую грудь.
Всем успехов в тренировках!
Какие мышцы прорабатываются?
С помощью «бабочки» мы работаем над большой и малой частью грудной мышцы в связке с плечевыми, передними дельтами, широчайшими, «трапецией», мышцами-вращателями плеча.
Польза
- Грудные мышцы приобретают пропорциональность, хорошо растягиваются, появляется четкая рельефность, особенно у тех, кто работает на массу.
- Упражнение помогает эффективно проработать глубокие участки груди, восстановить тонус верхней части туловища.
- Происходит равномерная нагрузка, а также разделение правой и левой грудной мышцы.
- Усиливается циркуляция крови, что приводит к наращиванию мышечной массы.
- «Бабочка» полезна для девушек и женщин — упражнение приводит грудь в тонус, повышает ее упругость.
Вред
При неправильном выполнении тренировки с рывками и «подпрыгиваниями», несоблюдении контроля над снарядом увеличивается травмоопасность для суставов. Необходимо следить за дыханием, адекватно подбирать веса, соблюдать технику, держать спину прямой, плечи параллельно полу, лопатки – сведенными. Нельзя бросать локти.
Пример тренировки с тренажером Пек Дек
Тренировка груди:
- Разминка: выполняем вращение дельтами 3х20, затем делаем жим лежа с пустым грифом — 2 подхода по 10 повторений.
- Жим штанги лежа — 3 подхода по 10 повторений.
- Жим лежа на наклонной скамье — 3 подхода по 10 повторений.
- Сведение рук в тренажере пек дек — 3 подхода по 12 повторений.
Тренировка плеч:
- Разминка: сначала вращение дельтами 3х20, затем отжимания от пола 2х8.
- Армейский жим стоя — 3 подхода по 10 повторений.
- Разведение гантелей в стороны (махи с гантелями) — 2 подхода по 10 повторений.
- Отведение рук назад в тренажере пек дек — 3 подхода по 12-15 повторений.
Сведение рук в тренажере «Бабочка»: техника выполнения
Сведение рук в тренажере или «Бабочка» представляет собой вспомогательное упражнение для тренировки грудных мышц. Данное движение выполняется в тренажере «Пэк-Дэк» и подходит для атлетов начального и среднего уровня подготовки.
Основные рабочие мышцы: большая и малая грудная, передние пучки дельтовидных мышц, передняя зубчатая мышца.
Правильная техника выполнения
- Займите положение сидя в тренажере «Пэк-Дэк»;
- Возьмитесь за рукояти и упритесь предплечьями в подушки, расположив плечи на уровне чуть ниже горизонтали;
- Выпрямите спину и начинайте сводить руки перед собой, выдерживая небольшую паузу в верхней точке упражнения;
- Медленно возвращайтесь в исходное положение;
- Выполните требуемое количество повторений.
Практические советы и рекомендации
- При выполнении сведений рук «Бабочка» не используйте силу инерции, а старайтесь выполнять упражнение исключительно за счет силы грудных мышц;
- Поддерживайте умеренный темп выполнения упражнения, не стремитесь выполнить повторения как можно быстрее;
- При разведении рук и опускании веса не ставьте его на опору, а удерживайте отягощение в воздухе – это исключит силу инерции и позволит повысить эффективность упражнения;
- В точке максимального сведения рук обязательно задержитесь на 1-2 секунды и только после этой паузы возвращайтесь в исходное положение;
- Делайте акцент на негативной фазе упражнения, это означает, что старайтесь опускать отягощение в медленном темпе и акцентировано;
- Используйте сведение рук «Бабочка» в конце комплекса для тренировки грудных мышц, выполняя 12-15 повторений.
Видео по теме: «Правильное выполнение сведений рук в тренажере (Бабочка)»
Сведение рук в тренажере
Сведение рук в тренажере – это одно из наиболее распространенных упражнений для тренировки грудных мышцы, выполняемое в тренажере. Само собой оно является изолирующим упражнением, способным акцентировано нагрузить определенный участок грудных мышц, при этом, практически не задействует другие мышечные группы, хотя без этого и не обошлось. Тем ни менее, упражнение хорошо ещё и тем, что оно позволяет растянуть грудные мышцы, а также смещать акцент нагрузки на различные пучки, поэтому это упражнение любят выполнять девушки.
Сведение рук в тренажере отлично развивает грудную клетку, но не стоит рассчитывать на то, что Вы сможете накачать грудь этим упражнением, в его функции входит формирование пропорций, а не рост мышечной массы. Вам следует выполнять это упражнение в конце тренировки, после того, как Вы достаточно нагрузите свои грудные мышцы, либо его можно использовать для предварительного утомления, впрочем, поскольку упражнение позволяет не только нагрузить, но и растянуть мышцы, то лучше его выполнять в конце. С помощью сведений Вы сможете накачать широкую, пропорциональную грудь, а также развить эластичность и гибкость мышц.
Работа мышц и суставов
Сведение рук в тренажере нагружает в основном внешнюю часть грудных мышц, растягивая их, что, собственно, и позволяет немного расширить грудную клетку. Именно поэтому очень хорошо совмещать это упражнение с пуловером и приседаниями с небольшим весом, когда Вы работаете над шириной костяка. Важно отметить, что проводить такие тренировки имеет смысл только тогда, когда у атлета ещё не закрыты зоны роста костей, то есть лет до 25. Кроме грудных, небольшую нагрузку получает также бицепс, который удерживает тренажер, поэтому выполняет функцию стабилизатора.
Суставы, конечно, получают некоторую нагрузку, но именно то, что упражнение анатомически является очень комфортным, и является преимуществом сведений рук в тренажере перед теми же разведениями гантелей. Вследствие такой комфортабельности, упражнение рекомендуется выполнять новичкам, у которых плохо развиты нейросвязь между мозгом и мышцами. Но несмотря на то, что суставы не подвержены большой нагрузке, выполнять упражнение следует после того, как Вы разомнетесь, а само упражнение следует делать подконтрольно и не спеша.
1) Настройте тренажер так, чтобы Вам было комфортабельно на нем сидеть, при этом, твердо упираться ногами в пол, или подставку.
2) Сядьте на стул, прогнув спину и выставив грудь вперед, при этом голова обязательно должна смотреть вперед, чтобы Вы не круглили позвоночник.
3) Вам следует глубоко вдохнуть воздух, а затем, на выдохе, притянуть руки друг к другу, сокращая грудные мышцы.
4) Во время пикового сокращения мышц, Вы должны немного задержаться, а затем вернуть мышцы в исходное положе, растягивая их, как можно сильнее.
5) Упражнение следует выполнять в диапазоне 12-15 повторений, чтобы Вы успели утомить мышцы.
Сведение рук в тренажере – примечания
1) Старайтесь локти все время держать немного согнутыми, что обеспечит лучший контроль тренажера на протяжении всей амплитуды движения.
2) Не доводите тренажер до мертвой точки ни тогда, когда разгибаете руки, ни тогда, когда сгибаете, поскольку таким образом Вы перенесете нагрузку с мышц в суставы.
4) Важно обеспечить себе твердую опору, чтобы не отвлекаться на координацию положения тела, так что, если не дотягиваетесь ногами до пола, то не стесняйтесь использовать подставку.
5) Упражнение следует выполнять обязательно в большом количестве повторений, не стремясь в увеличению веса на снаряде, поскольку целью упражнения не является рост мышечной массы, или силовых показателей, а «добивка» целевых мышечных групп.Анатомия
Сведение рук в тренажере прокачивает одну из самых больших мышечных групп в теле человека, поэтому очень важно суметь нагрузить её достаточно. В связи с тем, что использовать большие рабочие веса во время изолирующих упражнений не получается, то существует необходимость увеличивать интенсивность нагрузки, поэтому упражнение следует делать в большом количестве повторений и подходов. С другой стороны, сведение рук прокачивает только часть грудных мышц, при этом, правда, растягивает их, в связи с чем упражнение полезно выполнить в конце тренировки для того, чтобы окончательно «добить» грудь.
Поскольку упражнение является изолирующим, то суставы нагружаются не очень сильно, а комфортабельное положение тела, обеспечиваемое тем, что сведение рук выполняется в тренажере, помогает достичь наилучшей концентрации нагрузки именно в целевых мышечных группах. В общем, подводя итоги можно сказать, что упражнение является отличным способом растянуть грудные мышцы, а также довести их до позитивного отказа, но не помогает нарастить мышечную массу, вместо чего улучшает их качество.
Упражнения
СВЕДЕНИЕ РУК В ТРЕНАЖЕРЕ БАБОЧКА
Сведение рук на тренажере «бабочка» это превосходное изолирующее упражнение для мышц груди. Выполнение сведения рук в тренажере крайне эффективно для развития внутренней области груди и способствует созданию отчетливого разделения между грудными мышцыми. Для выполнения этого упражнения вам понадобится специальный тренажер «бабочка» или по-другому «баттерфляй», который есть почти в каждом тренажерном зале.
Задействованные мышцы: большие грудные мышцы.
Техника выполнения сведения рук в тренажере «бабочка»
Сядьте на скамью тренажера «бабочка», предварительно отрегулирував ее высоту. Выпрямитесь и прижмитесь спиной к спинке тренажера. Ноги примерно на ширине плеч, плотно прижаты к полу. Руки расположите на рукоятках тренажера. Локти должны быть примерно на уровне середины груди.
На выдохе напрягите грудные мышцы и равномерно сведите локти вместе. Задержитесь в таком положении одну-две секунды, дополнительно статически напрягая мышцы, затем медленно разведите руки, делая при этом вдох. Выполните 3-4 подхода по 8-15 повторений в каждом.
Примечания к выполнению сведения рук в тренажере
1. Не используйте чрезмерно тяжелый вес отягощения. Если вы не можете до конца свести локти и при этом наклоняетесь вперед, нужно немного снизить рабочий вес.
2. Во время выполнения упражнения следите за тем, чтобы ваша спина не отрывалась от спинки тренажера. Наклоном корпуса вперед вы себе помогаете, тем самым уменьшаете нагрузку на грудные мышцы.
3. Концентрируйтесь именно на сведении локтей и максимальном сокращении грудных мышц.
4. Начинайте движениие медленно, без резких движений. Недопускайте «разгон» отягощения и движения по инерции.
5. В нижней точке амплитуды движения, когда ваши локти разведены, полностью не опускайте отягощение, чтобы ваши грудные были напряжены на протяжении всего сета.
Другие упражнения для груди:
- Жим штанги лежа
- Жим лежа на наклонной скамье
- Жим гантелей лежа
- Разведение гантелей лежа
- Пулловер с гантелей
- Сведение рук в кроссовере
Сведение рук на тренажере
Сидя на тренажере. Руки держать в горизонтальном положении, локти упереть в рычаги, предплечья и запястья расслабить:
— сделать вдох и свести руки как можно ближе друг к другу;
— сделать выдох по окончании движения.
Это упражнение разрабатывает большие грудные мышцы. Во время сведения локтей оно локализует усилие на уровне внутренней части мышц груди, также разрабатывая клювовидно-плечевые мышцы и короткую головку бицепсов.
Это упражнение рекомендуется начинающим, так как позволяет достаточно окрепнуть перед выполнением упражнений с более сложными движениями.
Сведение верхних блоков «cross-over»
Стоя. Ноги поставить врозь. Туловище немного наклонить вперед. Руки развести в стороны, держать рукоятки тренажера и слегка согнуть в локтях:
— сделать вдох и подтянуть тросы, сведя руки перед собой, до касания их друг с другом;
— сделать выдох по окончании движения.
Это упражнение превосходно развивает большую грудную мышцу. Меняя угол наклона туловища и траекторию движения рук, то есть, сближая руки на различном по высоте уровне можно задействовать все части большой грудной мышцы.
Тяга гантели из-за головы лежа «pull-over»
Лежа на скамье. Ноги поставить на пол. Держать одну гантель обеими кистями на прямых руках; расположив ладони на внутренней поверхности дисков гантели. Рукоятку гантели обхватить большими и указательными пальцами обеих рук:
— сделать вдох и опустить гантель за голову, слегка сгибая локти, затем вернуться в исходное положение, выпрямляя руки;
— по окончании движения сделать выдох.
Это упражнение развивает внутреннюю часть большой грудной мышцы, длинную головку трицепсов, большую круглую мышцу, широчайшую мышцу спины, а также переднюю зубчатую, ромбовидную и малую грудную мышцы. Эти три последние мышечные группы придают лопаткам стабильное положение.
Это упражнение можно выполнять для укрепления грудной клетки.
Чтобы не перегружать трицепс, используют легкие гантели.
По возможности ложитесь поперек горизонтальной скамьи, чтобы уровень таза был опущен ниже уровня плечевого пояса.
Очень важно перед движением делать глубокий вдох, а выдох — только в самом конце движения.
Тяга штанги лежа «pull-over»
Лежа на скамье. Ноги поставить на пол. Держать гриф штанги прямыми руками хватом сверху не шире плеч:
— сделать вдох, максимально наполнить легкие воздухом, опустить штангу за голову, слегка сгибая руки в локтях;
— по окончании движения, возвращаясь в исходное положение, сделать выдох.
Это упражнение развивает большую грудную мышцу, длинную головку трицепсов, большую круглую мышцу; широчайшую мышцу спины, а также передние зубчатые мышцы, ромбовидную мышцу и малую грудную мышцу.
Оно великолепно расширяет грудную клетку.
Выполняя его, используйте нагрузки с легким весом и следите за положением туловища и правильным дыханием.
Возьмите предлагаемые упражнения за основу, развивайте их, учитесь у других спортсменов, и вскоре Вы сами сможете рассказать другим как накачать грудь или мышцы груди.
17
Что такое сходимость в конечно-элементном анализе? SimScale
Типичное инженерное проектирование включает прогнозирование прогибов / смещений, напряжений, собственных частот, распределения температуры и т. Д. Эти параметры используются для повторения параметров материала и / или геометрии для оптимизации их поведения. Традиционные методы, такие как ручные вычисления, предполагали идеализацию физических моделей с использованием простых уравнений для получения решений. Однако эти приближения упрощают проблему, и аналитическое решение может дать только консервативные оценки.В качестве альтернативы, FEM и другие численные методы предназначены для обеспечения инженерного анализа, который учитывает гораздо более подробную информацию, что было бы непрактично при ручных расчетах. FEM делит тело на более мелкие части, обеспечивая непрерывность перемещений вдоль границ этих элементов. Более подробную информацию о том, «как работает FEM» и «как изучить FEM», можно найти в соответствующих статьях SimScale.
Конвергенция в FEA
Что такое конвергенция в анализе методом конечных элементов (FEA)?Для тех, кто использует анализ методом конечных элементов, часто используется термин «сходимость».Большинство линейных задач не требуют итеративной процедуры решения. Конвергенция сетки — важная проблема, которую необходимо решить. Кроме того, в нелинейных задачах также необходимо учитывать сходимость итерационной процедуры. Итак, что это значит? В этой статье мы исследуем и решаем вопросы, связанные с этим термином.
Чтобы прочитать более общую статью об анализе методом конечных элементов, мы хотели бы отослать вас к SimWiki, где мы подробно обсуждаем важные темы инженерного моделирования.
Сходимость в FEA
Сходимость сетки: h- и p-уточнение в анализе методом конечных элементовОдной из наиболее часто игнорируемых проблем вычислительной механики, влияющих на точность, является сходимость сетки. Это связано с тем, насколько маленькими должны быть элементы, чтобы на результаты анализа методом конечных элементов не повлияло изменение размера сетки.
Рис. 01: Сходимость количества при увеличении степеней свободыКак показано на рис.01, очень важно сначала определить интересующее количество. Необходимо учитывать по крайней мере три точки, и по мере увеличения плотности сетки интересующее количество начинает сходиться к определенному значению. Если два последовательных уточнения сетки существенно не меняют результат, можно предположить, что результат сходился.
Рис. 02: Уточнение сетки структурыГоворя об уточнении сетки, не всегда необходимо уточнять сетку всей модели.Принцип Сен-Венана требует, чтобы локальные напряжения в одном регионе не влияли на напряжения в другом месте. Следовательно, с физической точки зрения модель может быть уточнена только в определенных областях, представляющих интерес, и, кроме того, иметь зону перехода от крупной сетки к мелкой. Существует два типа уточнений (h- и p-уточнение), как показано на рис. 02. H-уточнение относится к уменьшению размеров элементов, а p-уточнение относится к увеличению порядка элемента.
Однако важно различать геометрический эффект и конвергенцию сетки.В частности, при построении сетки изогнутой поверхности с использованием прямых (или линейных) элементов, что потребует большего количества элементов (или иного уточнения сетки) для точного захвата границы. Как показано на рис. 03, уточнение сетки приводит к значительному снижению ошибок.
Рис. 03: Уменьшение ошибки с помощью h-уточнения криволинейной поверхностиТакое уточнение может позволить увеличить сходимость решений без увеличения размера решаемой проблемы в целом.
FEA
Конвергенция при наличии сингулярностейПосле прочтения вышеупомянутого раздела можно с уверенностью предположить, что, как только напряжение сходится в определенной части конструкции, использование того же размера элемента в другом месте должно привести к сходимым решениям.Однако это неверное предположение.
Большинство моделей имеют углы, как внутренние, так и внешние, радиус которых считается равным нулю. То же самое и при наличии трещин. В этих случаях напряжения теоретически бесконечны. Теперь вы можете догадаться, почему иллюминаторы самолетов не имеют углов, а закруглены по краям?
Рис. 04 Сингулярность напряженийПри наличии сингулярности сетку необходимо уточнять вокруг нее. Однако, как показано на рис. 04, чем больше уточняется сетка, тем сильнее напряжение продолжает увеличиваться и стремится к бесконечности.
Следовательно, при наличии скруглений, как правило, более разумно принять фактический радиус, а затем уточнить область, используя достаточное количество элементов. Для получения дополнительных сведений об особенностях сетки мы рекомендуем нашу недавнюю статью в блоге SimScale под названием «Влияние размера сетки на концентрацию механического напряжения».
Шлем предназначен для защиты человека, который его носит, от травмы головы во время удара. В этом проекте анализа методом конечных элементов удар человеческого черепа со шлемом и без него моделировался с помощью нелинейного динамического анализа.Загрузите это исследование бесплатно.
Анализ методом конечных элементов
Сходимость во время блокировкиДругая часто встречающаяся нелинейная проблема связана с блокировкой, а именно с эффектами объемной блокировки и блокировки при сдвиге. Объемная блокировка обычно встречается в задачах, связанных с несжимаемостью, в задачах гиперупругости и пластичности. Альтернативно, блокировка сдвигом обычно встречается в задачах, связанных с изгибом.
Для более подробного обсуждения объемной блокировки и блокировки сдвига вы можете обратиться к нашим статьям в блоге SimScale: «Моделирование эластомеров» и «Создание сетки в МКЭ» соответственно.
На рис. 05 показана стандартная задача при испытании несжимаемых эффектов. Как показано, рассматривается небольшая труба с внутренним давлением. Такие приложения обычно встречаются в различных средах, включая артерии человека. Только четверть модели требует рассмотрения из-за симметрии задачи. Когда коэффициент Пуассона стремится к 0,5, объемный модуль упругости стремится к бесконечности, и, таким образом, материал демонстрирует несжимаемость. В этом случае предпочтительны элементы второго порядка или, другими словами, требуется p-уточнение.На рисунке также показано поведение различных типов элементов при увеличении коэффициента Пуассона.
Рис. 05: Стандартная задача с внутренним давлением, рассматриваемая для проверки объемной блокировки (вверх) и сходимости в задачах объемной блокировкиАналогичным образом, на рис. 06 показана простая задача изгиба балки, когда на свободный конец прилагается момент. Учитывается прогиб на свободном конце балки, и эта задача даже имеет аналитическое решение для сравнения. Инжир.06 показывает сходимость прогиба для различных типов элементов.
Рис.06: Блокировка сдвига в задаче изгиба балки и сходимости для различных элементовКонвергенция FEA
Как измерить конвергенциюИтак, теперь, когда важность конвергенции обсуждалась, как ее можно измерить? Что такое количественная мера конвергенции? Один из способов измерить это — сравнить с аналитическими решениями или экспериментальными результатами.
Рис. 07: Определение ошибокКак показано на Рис.07 можно определить несколько ошибок для смещения, деформаций и напряжений. Эти ошибки можно использовать для сравнения, и их нужно будет уменьшить с помощью уточнения сетки. Однако в сетке МКЭ величины вычисляются в различных точках (узловых и гауссовых). В таком случае, где и в каком количестве точек должна быть рассчитана ошибка?
Рис. 08: Норма ошибки и сравнение с размером элементаВ качестве альтернативы нормы определяются таким образом, чтобы можно было рассчитать усредненные ошибки по всей конструкции или ее части.Как показано на рис. 08, нормы погрешности также можно сравнить с размером элемента. Здесь « c » — это константа пропорциональности, а « h » — размер элемента, как определено на рис. 08. Следовательно, несколько ошибок, таких как L2 и нормы энергетической погрешности, могут быть определены следующим образом:
Однако в реальных практических приложениях безразмерная версия того же самого более полезна для оценки фактической степени ошибки. Следовательно, в этом случае среднеквадратичное значение норм, как определено ниже, используется для построения графика уменьшения ошибки.
Последняя тема связана со скоростью, с которой эти ошибки в идеале уменьшаются. Если мы используем линейные, квадратичные или кубические элементы, как можно судить о том, уменьшается ли ошибка при правильной скорости или качестве закодированных алгоритмов? Как показано на рис. 09, ошибка L2-нормы уменьшается со скоростью p + 1 , а энергетическая норма — со скоростью p.
Рис.09: Степень сходимости для различных норм ошибок в анализе методом конечных элементовКонвергенция в ВЭД
ЗаключениеЯ надеюсь, что эта статья дала всесторонний обзор сходимости, скорости сходимости и способов точной оценки этих аспектов в анализе методом конечных элементов.Сходимость играет важную роль в точности решений, полученных с помощью численных методов, таких как FEA, и поэтому требует всестороннего анализа в любой данной задаче.
Узнайте, как получить легкий доступ к облачным инструментам для САПР и моделирования, посмотрев запись вебинара «Как оптимизировать медицинские устройства с помощью облачного моделирования» в партнерстве с Onshape. Все, что вам нужно сделать, это заполнить эту короткую форму, и она начнется автоматически.
Конвергенция технологий в правительстве
Пределы использования одной технологии
«Хорошо, Хьюстон, у нас тут проблема. 1 Теперь известные слова были переданы через космос в Хьюстон после того, как экипаж «Аполлона-13» попытался перемешать криогенные кислородные баллоны. В остальном стандартная процедура вызвала серию коротких замыканий и последующих проблем, в результате чего командный модуль не смог вырабатывать электроэнергию, подавать кислород или производить воду. Ситуация, связанная с космическим пространством в тысячах миль от Земли, была ужасной для экипажа Аполлона-13.
У наземных инженеров НАСА было очень мало информации.Экипаж поделился своими наблюдениями, и космический корабль передавал некоторые данные, но эти данные не давали инженерам на земле идеальной картины. Чтобы лучше понять, что произошло и с какими последствиями столкнулась команда, команда НАСА в Хьюстоне использовала зеркальную систему космического корабля Apollo 13, что позволило им максимально точно воспроизвести ситуацию. НАСА фактически создало двойника — в данном случае аномалию и все такое — над которым они могли работать в космическом центре в Хьюстоне. 2 Действительно, с информацией, полученной из этой системы, инженеры в Хьюстоне смогли разработать решение, модифицировав воздушный фильтр, что позволило экипажу Аполлона-13 безопасно вернуться на Землю 17 апреля 1970 года.
Что, если бы команда в Хьюстоне имела доступ к большему количеству данных в режиме реального времени; доступ к виртуальной реальности для проверки, тестирования и решения проблем; и AI для выявления проблем до того, как они возникли, независимо от расстояния? Возможно, в космическом корабле никогда бы не произошло короткого замыкания, и миссия продолжилась бы, как и планировалось. В 1970 году таких систем не существовало, но они есть сегодня.
Эти современные технологии могут дополнять друг друга, предлагая новые возможности для визуализации, обучения, информирования, коммуникации, сотрудничества и участия в планировании сложных систем и операций.Но такие системы не являются единичными технологиями. Скорее, они состоят из цифровых двойников, искусственного интеллекта и иммерсивных технологий, таких как виртуальная реальность (VR) и дополненная реальность (AR).
По мере того, как руководители правительств движутся к следующему технологическому горизонту, очень важно понимать, как технологии, используемые вместе, могут создавать новые возможности. Если руководители правительства сосредоточатся исключительно на отдельных технологиях для решения отдельных задач, они потенциально рискуют купить их без необходимой поддержки или инфраструктуры.Такие технологии, как AI, VR / AR и цифровой двойник, могут работать вместе, открывая захватывающие и новые возможности для правительства — например, поддержку принятия решений в реальном времени и моделирование путешествия страны на Луну. Достижение этой цели требует не только типичного межфункционального сотрудничества между лидерами, но и понимания предстоящей технологической конвергенции и того, как лучше всего извлечь из этого выгоду.
Что это за новые технологии?
В связи с тем, что каждый день вводится так много разных технологических терминов, может быть трудно понять, что такое новая технология на самом деле, и, что не менее важно, чем она не является.Здесь мы сосредоточимся на некоторых из них, которые могут стать ключевыми компонентами конвергенции технологий.
Цифровая реальность
Цифровая реальность — это наш термин для обозначения ряда иммерсивных технологий, которые переносят цифровую информацию в физический мир, включая AR, VR, смешанную реальность, 360-градусное видео и возможности погружения (рисунок 1).
Цифровой двойник
Цифровой двойник, как мы писали в другом месте, — это «развивающийся цифровой профиль исторического и текущего поведения физического объекта или процесса, который помогает оптимизировать производительность бизнеса.” 3 Это точная цифровая копия физического объекта, приносящая преимущества цифрового анализа в физический мир (рис. 2).
Приложения цифрового двойника включают, но не ограничиваются:
- Производство — моделирование или имитация физических систем для оптимизации
- Авиация — профилактическое обслуживание
- Здравоохранение — оптимизация жизненного цикла больницы
- Городское развитие — оптимизация и тестирование без риска
Искусственный интеллект
Возможно, не существует единого общепринятого определения ИИ, но хорошее определение — это технологии, которые могут выполнять и / или дополнять задачи, лучше информировать решения и достигать целей, которые традиционно требовали человеческого интеллекта, таких как планирование, рассуждение частичная или неопределенная информация и обучение.Инструменты искусственного интеллекта часто можно классифицировать как по тому, как они работают, так и по тому, что они делают (рисунок 3).
Палитра технологий
Развитие технологий часто приводит к разрозненным решениям: одна проблема, одно технологическое решение. Телефон помогал людям преодолевать расстояния и общаться в режиме реального времени. Интернет позволил людям получить доступ к объемам информации, которая иначе была бы недоступна. А цифровая камера изменила то, как люди запечатлевают моменты и воспоминания с помощью фотографий.Но настоящее революционное развитие произошло, когда эти инструменты были объединены в одно устройство, такое как смартфон. Посредством конвергенции технологий пользователи разрабатывают новые инструменты, методы и решения, которые повышают эффективность процессов, экономят деньги и приводят к дальнейшим инновациям.
Пока что VR / AR, искусственный интеллект и цифровые двойники используются в основном как «решение одной проблемы и одной технологии». По отдельности эти технологии предлагают новые решения множества различных проблем. Например, виртуальная реальность используется для ускорения обучения с помощью иммерсивных и реалистичных сценариев.Цифровые двойники могут увеличить производительность и позволяют командам более точно контролировать сложные физические системы. Искусственный интеллект вырос до такой степени, что может анализировать горы данных и производить выводы быстрее, чем люди. Хотя эти технологии обладают огромным потенциалом даже в виде изолированных решений, таких как смартфон, их конвергенция обещает еще большие возможности.
Действительно, мы уже видим ценность их сближения. Например, Управление энергетики и водоснабжения Дубая в партнерстве с Siemens объединило искусственный интеллект и машинное обучение с термодинамической цифровой двойной газовой турбиной, чтобы повысить эффективность работы и сэкономить примерно 4 доллара США.6 миллионов долларов ежегодно. 4 Цифровой двойник предоставляет информацию о конкретных компонентах или проблемах в режиме реального времени, в то время как компонент ИИ может обрабатывать огромный объем данных, чтобы уведомить системных менеджеров о возникающих проблемах или о том, когда лучше всего проводить техническое обслуживание.
В компании Aveva, занимающейся разработкой и производством программного обеспечения, удаленные инженерные группы используют гарнитуры виртуальной реальности и цифрового двойника, чтобы направлять команды на местах через диагностические и восстановительные процессы. 5 Вместо того, чтобы определять проблему и пытаться сообщить сложную ситуацию по телефону или электронной почте, комбинация цифрового двойника и виртуальной реальности позволяет удаленным инженерам точно видеть, что происходит в режиме реального времени. Виртуальная трехмерная презентация значительно улучшает общение, что упрощает диагностику или устранение недостатков. 6
Конвергенция этих технологий не ограничивается крупными производственными процессами или компаниями. Цифровые двойники и иммерсивные технологии оказались фантастическими инструментами для правительств при реагировании на стихийные бедствия.В 2018 году, когда 12 юных футболистов и их тренер оказались в ловушке в пещере из-за поднимающегося паводка, спасатели объединили несколько источников данных, чтобы создать трехмерного цифрового двойника пещеры. 7 Это помогло рассчитать, как лучше всего отвести воду для осушения пещеры, понять, где могут быть другие точки доступа, и помочь дайверам рассчитать, какие области будут затоплены и каковы будут их потребности в воздухе. За почти три недели спасательной операции эти модели оказались жизненно важными для безопасного спасения мальчиков и их тренера.
Преимущества этой конвергенции ИИ, цифрового двойника и AR / VR ощутят на себе правительства, частный сектор и общественность, потому что ценность этих технологий, используемых вместе, будет только расти. Понимание того, как произойдет это сближение и как лучше всего подготовиться, будет важно не только для экономии времени и денег при покупке сегодняшних технологий, но и для открытия совершенно новых возможностей для решения самых больших проблем правительства завтра.
Технологии не просто сходятся; ему
нужно , чтобы сойтисьТехнологическая конвергенция означает, что ранее независимые технологии необходимо разрабатывать и покупать друг с другом.Это может создать потенциальные ловушки для руководителей правительства. Правительство больше не может покупать единственную технологию для единственной проблемы; это может создать риски дорогостоящего дублирования, потери возможностей и ограниченных возможностей для будущего развития.
Риск №1: Отсутствие необходимых возможностей
Конвергенция означает, что передовые технологии все больше полагаются друг на друга для правильного функционирования. Преследование каждого из них по отдельности рискует упустить из виду ключевой компонент. Например, во многие из сегодняшних военных игр все еще играют в кости на столе, в основном это индивидуальная настольная игра.Эти настольные игры доказали свою стойкость к компьютеризации на протяжении многих лет, в основном потому, что простого внедрения некоторых продвинутых версий этих игр с искусственным интеллектом недостаточно для повышения их производительности. Играм также требуются большие объемы реальных данных, чтобы гарантировать, что они точно представляют реальные машины во время войны. По словам подразделения Wargaming корпуса морской пехоты США: «В настоящее время мы не собираем необходимые данные на систематической основе; нам не хватает процессов и технологий для анализа собираемых данных; и мы не используем имеющиеся у нас данные для определения пространства для принятия решений при укомплектовании, обучении и оснащении сил. 8 Другими словами, попытки улучшить военные игры с помощью искусственного интеллекта или цифровой реальности без включения реальных данных, которые могут поступать только от датчиков, обеспечивающих работу цифровых двойников, могут не дать лучших результатов, чем военные игры, основанные на играх в кости. используется сегодня.
Риск № 2: Дорогостоящее дублирование усилий
Правительствам не привыкать к разрозненности или дублированию усилий, но они могут быть особенно разрушительными для небольших правительств. Один крупный ИТ-проект или капитальные вложения могут потреблять значительную часть бюджета государственного учреждения.Так что, если эти инвестиции будут сделаны в инструмент, который уже доступен где-то еще, это может быть значительной упущенной возможностью. В качестве примера возьмем только ИИ: когда Департамент обслуживания детей, молодежи и их семей штата Делавэр (DSCYF) модернизировал свою систему управления делами, ему потребовались поисковые устройства и системы рекомендаций ИИ. 9 Обнаружив существующие инструменты, которые уже используются другими агентствами в облаке, DSCYF смогла сэкономить время и деньги при развертывании. Хотя эта проблема не нова, конвергенция технологий делает ее еще более острой.Теперь правительственным руководителям необходимо не только проверять существующие технологии одного типа, им также необходимо проверять наличие нескольких типов технологий во многих различных областях, от обучения до моделирования и приобретения, чтобы убедиться, что нет существующих инструментов, которые могут соответствовать друг другу. их потребности.
Риск № 3: Ограничения на будущее развитие
Наконец, даже если разработка одной технологии идет идеально без дублирования усилий или потери функциональности, этот успех может быть мимолетным, если не принимать во внимание другие технологии.Возьмем, к примеру, виртуальное обучение. Даже если виртуальная тренировочная среда имеет гиперреалистичные сцены и транспортные средства и может подключаться к самому продвинутому ИИ для тренировок людей без цифрового двойника, она может быть идеальным представлением только этого момента времени. Как только появятся новые машины или построены новые здания, вся тренировочная среда потребует значительных и дорогостоящих обновлений. Что необходимо, так это организационные, процедурные и технические связи для включения цифровых двойников новых транспортных средств и инфраструктуры.
С учетом того, что армия США тратит сотни миллионов на виртуальную тренировочную среду, министерство обороны тратит десятки миллионов долларов на новые возможности ведения военных действий, а правительство США инвестирует в географические информационные системы и другие инструменты по всей стране, есть немедленная необходимость сделать это правильно. 10
Три пути, один пункт назначения
Если конвергенция ИИ, AR / VR и цифровых двойников не только желательна, но и необходима, возникает вопрос, как на самом деле будет выглядеть такая конвергенция? Что он может сделать из нового? Короткий ответ: все зависит от того, что вам нужно.
Дом
Построй вещь
Добавление искусственного интеллекта и AR / VR к цифровому двойнику может открыть новые возможности на протяжении всего жизненного цикла всего, от резервуара до транзитной магистрали. Например, девелоперы коммерческой недвижимости уже используют эти технологии, чтобы лучше понять, как проект будет обретать форму и повлиять на окружающую среду или городской пейзаж, а также отслеживать его прогресс. 11 В более крупном масштабе Virtual Singapore представляет собой динамическую трехмерную модель города стоимостью 73 миллиона долларов США, которая после завершения будет способна поддерживать планирование, принятие решений, тестирование и исследования для решения некоторых из наиболее важных городских районов Сингапура. проблемы. 12 Хотя этот пример впечатляет, он все же не распространен среди всех разработчиков. А теперь представьте, использовалась ли эта технологическая конвергенция в масштабах для развития всего, от зданий и фабрик до городской инфраструктуры и военных баз.
Повысьте умение
Преимущества использования VR / AR для улучшения обучения, особенно при выполнении редких или опасных задач, хорошо задокументированы. 13 Однако добавление ИИ и цифровых двойников может дать поистине впечатляющие результаты. Например, программа ВВС США по обучению пилотов Next использует эти технологии, чтобы вдвое сократить время, необходимое для обучения пилотов. 14
Но даже эти впечатляющие результаты — только часть истории. Как только станет понятна сила технологической конвергенции, такие инструменты станут лабораториями для улучшения взаимодействия между людьми и машинами. Возьмем знаменитый пример Три-Майл-Айленда в Пенсильвании, где стресс рабочего, критическая сигнальная лампа, спрятанная за панелью, и другие факторы — все вместе привело к ядерному расплаву в 1979 году. 15 Если бы этот экипаж реактора мог обучаться этому. в виртуальной среде до аварии, возможно, они могли бы выявить эргономические проблемы, такие как скрытые кнопки и отработанные процессы, чтобы уменьшить стресс реальных аварийных ситуаций, возможно, даже избежать аварии в целом.
Понимание
Предсказать, что делать в будущем
Способность цифровой реальности, цифровых двойников и искусственного интеллекта связывать физический и цифровой миры делает их мощными инструментами для изучения мира вокруг нас. Угадать, как люди будут действовать в будущем, — задача, с которой сталкиваются как военные, так и градостроители. Создание цифрового двойника города или вооруженных сил может обеспечить гораздо более точное моделирование, чем современные статистические модели городов или военные игры, основанные на играх в кости.
Сан-Диего использует этот подход для борьбы с дорожным движением в центре города. Раньше он, вероятно, рассматривал только несколько проектов по расширению дорог для изучения, но теперь он может сравнивать многие варианты, включая скоростные железнодорожные линии или системы легкорельсового транспорта. И результаты, показывающие лучшие решения, могут быть получены в течение нескольких часов или дней, а не недель. Эти результаты могут затем показать заинтересованным гражданам, как именно работает новый город или предлагаемый строительный проект повлияет на них индивидуально — не на общую оценку, а на то, как это изменит их уникальную поездку на работу или вид на горизонт.
Другой серьезной проблемой для правительств и промышленности является оценка воздействия на окружающую среду и получение разрешений. Понимание всех воздействий предлагаемого проекта может быть трудным и либо замедлить необходимое развитие, либо поставить под угрозу хрупкие природные ресурсы. Но ИИ, цифровой двойник и цифровая реальность могут помочь. ИИ уже помогает правительствам понять влияние всего, от производства риса до производства, на сложные экосистемы. 16 Объединение этой информации с цифровым двойником может показать, как эти воздействия повлияют на конкретный город, а VR и AR могут помочь естественным образом визуализировать эти результаты как для градостроителей, так и для горожан.В результате процесс проверки может быть значительно ускорен, что позволяет ускорить разработку с меньшим воздействием на окружающую среду.
Знайте, что делать прямо сейчас
Возможно, окончательным выражением конвергенции ИИ, цифрового двойника и цифровой реальности является способность выполнять многие из тех же задач планирования и моделирования, но в режиме реального времени. Например, команды Формулы-1 используют цифровых двойников автомобилей и лазерное сканирование гоночных треков в сочетании с обширными алгоритмами машинного обучения и симуляторами «человек в контуре», чтобы придумать лучшие гоночные стратегии, чем у конкурентов. 17 Эти инструменты используются даже во время гонки, чтобы приспособиться к непредвиденным последствиям, таким как ливневый дождь или повреждение автомобиля.
Существует очевидное применение этой высокоинтенсивной поддержки принятия решений в кризисном управлении как для национальных, так и для городских руководителей. Мы исследовали, что это может означать, например, для аналитиков разведки, которые могут перейти от статических брифингов для национальных лидеров перед кризисом к встрече с лидерами во время кризиса, обновляя модели и давая советы в режиме реального времени. 18 Но эти преимущества применимы не только к серьезным кризисным ситуациям, но и к незначительным кризисам, таким как пробка на дороге с работы домой. Поддержка принятия решений в режиме реального времени может помочь менеджерам дорожного движения понять влияние аварии или неожиданного снегопада и отреагировать, чтобы минимизировать задержки в транспортной сети.
На рис. 5 представлены примеры того, как технологическая конвергенция может применяться по-разному в разных отраслях.
Что нужно для начала?
Потенциальные преимущества конвергенции ИИ, цифрового двойника и цифровой реальности впечатляют, но если они когда-либо станут чем-то большим, чем несбыточная мечта, организациям необходимо спросить себя: «Какой тип инфраструктуры требуется для этих технологий?».Передовые технологии, работающие в режиме, близком к реальному времени, для создания совершенно новых возможностей для правительств, звучат как технический кошмар, который может потребовать огромных капитальных вложений. Однако реальность может стать приятным сюрпризом для технических директоров.
Знать требования к вычислениям
Даже крупномасштабное моделирование целых городов или целых армий может не потребовать помещений, заполненных мэйнфреймами или целыми центрами обработки данных. Требования к вычислениям зависят не от количества или типов вещей в сценарии, а от того, сколько им нужно взаимодействовать. 19 Таким образом, даже некоторые очень большие симуляции могут быть выполнены очень быстро и недорого с ограниченными вычислительными требованиями. Фактически, некоторые из ранних экспериментов в инструменте городского планирования CityScope MIT Media Lab основывались на одном ноутбуке для запуска цифровых двойников, AI и AR для моделирования. 20
Найдите подходящие инструменты
Как только первоначальный страх перед затратами будет преодолен, вы сможете найти правильные инструменты, чтобы воплотить свое видение в жизнь. Это начинается с определения потребностей вашего бизнеса.По словам Джордана Гарретта из подразделения новых технологий Dell, «инфраструктура будет определяться тем, что вы хотите делать. Например, в сценариях использования для проектирования сложных деталей может потребоваться значительная централизованная мощная вычислительная поддержка для запуска всего автоматизированного проектирования (САПР) и моделирования. С другой стороны, во многих случаях использования на производстве может потребоваться более легкая модель граничного ядра-облака, которая может позволить различным предприятиям работать независимо ». 21
Ответьте на ваши вопросы, а не на все вопросы
При работе со сложными системами даже самые высокопроизводительные инструменты с лучшими ресурсами имеют свои пределы.Гоночные команды Формулы-1 обычно используют около 4000 серверов в облаке для моделирования гоночных стратегий в реальном времени и по-прежнему сталкиваются с ограничениями. По словам Рандипа Сингха, руководителя стратегии гонок McLaren F1: «Для одной расы существует больше вариантов развития расы, чем существует электронов во вселенной. Так что вы никогда не собираетесь моделировать все. Что мы стараемся и делаем, так это очень умно использовать элементы машинного обучения и теории игр, чтобы попытаться смоделировать то, что могут делать наши конкуренты, чтобы быть на шаг впереди них. 22 Для руководителей правительства это означает не моделирование каждой детали всех возможных вопросов — будь то город, война или вспышка болезни — а только те вопросы, которые наиболее актуальны и находятся в пределах вашего контроля.
Решите проблему с данными
Наконец, хотя технологическая инфраструктура может быть не такой большой и пугающей проблемой, как кажется на первый взгляд, данные могут быть еще более серьезными. ИИ, и цифровые двойники, и цифровая реальность хороши ровно настолько, насколько хороши данные, которые они получают.Чем сложнее сценарий, тем больше вероятность того, что данные будут поступать с нескольких платформ в разных форматах. Тем не менее, все это должно работать вместе. Очистка, форматирование и обеспечение возможности использования всех этих данных в течение периодов времени, необходимых для принятия важных решений, является важной задачей и заслуживает серьезного размышления перед тем, как приступить к решению.
Прежде всего, работайте вместе ради видения будущего
Легко думать о технологиях как о разовых решениях одной проблемы.От управления парусными судами до управления воздушным движением — самые сложные проблемы требуют непрерывного взаимодействия нескольких технологий. Для руководителей правительства это означает, что вы не можете думать о технологиях индивидуально — покупать VR для обучения здесь, цифрового двойника для приобретения здесь и AI для принятия решений здесь. Чем сложнее становятся эти технологии, тем больше они полагаются друг на друга. В результате правительственные лидеры должны рассмотреть возможность использования этих технологий с прицелом на эту конвергенцию, обнаруживая, как цифровые близнецы после приобретения нового самолета переходят в конвейер обучения пилотов виртуальной реальности или обновляют модели искусственного интеллекта, которые выполняют профилактическое обслуживание.
Это означает, что лидеры в области обучения, закупок и технологий должны работать вместе, чтобы понять свои индивидуальные цели и то, как конвергенция технологий может их коллективно решить. Игнорирование этой конвергенции потенциально чревато дублированием программ, несовместимыми системами и потерей времени и денег. Будущее не за горами, но его можно увидеть только вместе.
Устранение неполадок моделирования| Интерактивная документация по продуктам Altium
Если схема не моделируется, вы должны определить, проблема в схеме или в процессе моделирования.Следуйте информации, содержащейся в этом разделе справочника, и прорабатывайте предложенные пункты, пробуя по очереди.
Иногда во время моделирования отображается сообщение об ошибках или предупреждениях. Эти сообщения перечислены на панели Сообщения .
Предупреждающие сообщения
Предупреждающие сообщения не фатальны для моделирования. Обычно они предоставляют информацию об изменениях, которые SPICE пришлось внести в схему, чтобы завершить симуляцию.К ним относятся недопустимые или отсутствующие параметры и т. Д. Предупреждения Digital SimCode могут включать такую информацию, как нарушения синхронизации (tsetup, thold, trec, tw и т. Д.) Или значительные падения напряжения питания на цифровых компонентах. Правильные результаты моделирования обычно генерируются, даже если появляются предупреждения.
Сообщения об ошибках
Сообщения об ошибках предоставляют информацию о проблемах, которые SPICE не смогла решить и которые были фатальными для моделирования. Сообщения об ошибках указывают на то, что результаты моделирования не могут быть сгенерированы, поэтому их необходимо исправить, прежде чем вы сможете анализировать схему.
Устранение неполадок при создании списка соединений
Когда вы запускаете симуляцию, первое, что происходит, — это анализируется схема и генерируется список соединений SPICE. Этот список соединений затем передается механизму SPICE, который моделирует схему и генерирует результаты.
Все ошибки, обнаруженные при составлении списка соединений, перечислены на панели Сообщения . Вероятные причины ошибок в списке соединений:
- Компонент в исходном (-ых) документе (-ах) схемы, не содержащий информации моделирования.Чтобы проверить, подходит ли компонент для моделирования, дважды щелкните компонент на схеме, чтобы открыть его диалоговое окно Свойства компонента и убедитесь, что существует связанная имитационная модель в области Models диалогового окна.
- Файл имитационной модели, на который ссылается компонент, находится не в месте, указанном в области Местоположение модели на вкладке Тип модели диалогового окна Sim Model . Это могло произойти, если связанная интегрированная библиотека, в которой хранится модель, не установлена или была перемещена из исходного места установки.
Все библиотеки исходных компонентов устанавливаются в следующую папку:
\ Библиотека
Эта корневая папка включает в себя различные подпапки, содержащие интегрированные библиотеки компонентов от конкретных производителей, а также два общих файла интегрированных библиотек ( Miscellaneous Devices.IntLib и Miscellaneous Connectors.IntLib ), содержащие общие схемные компоненты (многие из которых являются имитационными) -готовы).
Папка \ Library \ Sim содержит различные файлы.txt и .scb для имитационных моделей на основе SimCode, таких как модели цифровых компонентов серии CMOS и 74XX.
Папка \ Library \ Simulation содержит следующие специальные интегрированные библиотеки компонентов, готовых к моделированию:
Simulation Math Function.IntLib
Simulation Sources.IntLib
Simulation Special Function.IntLib
Simulation Transmission Line.IntLib
- Путь к модели Digital SimCode (некомпилированный исходный файл (
*.txt) или скомпилированный файл (* .scb)), обозначаемый как{MODEL_PATH}, не соответствует местоположению модели. Это могло произойти, если модель переместить в другое место на жестком диске. Путь к модели определяется в диалоговом окне «Параметры моделирования» относительно папки «Библиотека» установки. По умолчанию это путь\ Library \ Sim \.
Неисправности при анализе моделирования при помощи
Одна из проблем всех симуляторов — конвергенция.Что именно подразумевается под термином «конвергенция»? Как и большинство симуляторов, движок SPICE симулятора на базе Altium Designer использует итерационный процесс многократного решения уравнений, которые представляют вашу схему, чтобы найти напряжения и токи в контуре покоя. Если ему не удается найти эти напряжения и ток (не удается сходиться), он не сможет выполнить анализ схемы.
SPICE использует одновременные линейные уравнения, выраженные в матричной форме, для определения рабочей точки (постоянного напряжения и тока) схемы на каждом этапе моделирования.Схема сводится к массиву проводимостей, которые помещаются в матрицу, чтобы сформировать уравнения ( G * V = I ). Когда схема включает нелинейные элементы, SPICE использует несколько итераций линейных уравнений для учета нелинейностей. SPICE делает первоначальное предположение относительно узловых напряжений, а затем вычисляет токи ответвления на основе проводимости в цепи. Затем SPICE использует токи ответвления для пересчета узловых напряжений, и цикл повторяется. Этот цикл продолжается до тех пор, пока все напряжения узлов и токи ответвлений не попадут в указанные допуски (не сойдутся).
Однако, если напряжения или токи не сходятся в течение указанного числа итераций, SPICE выдает сообщения об ошибках (например, сингулярная матрица , Gmin сбой шага , исходный шаговый шаг не удалось или предел итераций достиг ) и прерывается. моделирование. SPICE использует результаты каждого шага моделирования как начальные предположения для следующего шага. Если вы выполняете переходный анализ (то есть время увеличивается) и SPICE не может найти решение с использованием указанного временного шага, временной шаг автоматически уменьшается, и цикл повторяется.Если временной шаг сокращен слишком сильно, SPICE отображает сообщение слишком маленький временной шаг и прерывает симуляцию.
Устранение неполадок общего моделирования
Когда анализ моделирования дает сбой, наиболее распространенной проблемой является неспособность схемы сходиться к разумной рабочей точке. Используйте следующие методы для решения проблем сходимости.
Действия по устранению неполадок сходимости
- При возникновении проблемы сходимости сначала отключите все анализы, кроме анализа рабочих точек.
- Обратитесь к панели сообщений для получения информации об ошибках / предупреждениях, связанных с моделированием.
- Убедитесь, что цепь подключена правильно. Свисающие узлы и случайные детали не допускаются.
- Убедитесь, что в цепи есть узел заземления, и что каждый узел в цепи имеет путь постоянного тока к этому заземлению. Компоненты, которые могут изолировать узел, включают трансформаторы и конденсаторы. Источники напряжения считаются коротким замыканием постоянного тока, источники тока — разомкнутой цепью постоянного тока.
- Убедитесь, что нули не перепутали с буквой O при вводе параметров моделирования.
- Убедитесь, что заданы правильные множители SPICE (MEG вместо M для 1E + 6) для любых значений компонентов или параметров моделирования. Множители не чувствительны к регистру. Также не допускаются пробелы между значениями и множителями. Например, оно должно быть 1,0 мкФ, а не 1,0 мкФ.
- Убедитесь, что для всех устройств и источников установлены правильные значения.
- Убедитесь, что усиление любого зависимого источника установлено правильно.
- Временно удалите последовательные конденсаторы или источники тока и повторно запустите моделирование.
- Временно удалите параллельные катушки индуктивности или источники напряжения и повторно запустите моделирование.
- На странице SPICE Options диалогового окна Analyses Setup (на схеме выберите Design »Simulate» Mixed Sim , затем щелкните запись Advanced Options в списке Analyses / Options ), увеличьте значение параметра
ITL1на300.Это позволит выполнить больше итераций анализа рабочих точек, прежде чем отказаться от него. - Добавьте устройства .NS (Nodeset) для определения узловых напряжений. Если первоначальное предположение об узловом напряжении далекое, устройство .NS можно использовать для предварительного определения начального напряжения, которое используется для предварительного прохождения анализа рабочей точки.
- Если устройство Nodeset не способствует сходимости, попробуйте определить начальные условия, разместив устройства .IC. В этом случае напряжения узлов поддерживаются на заданных значениях во время анализа рабочих точек, а затем сбрасываются во время анализа переходных процессов.
- Включите опцию Use Initial Conditions на странице Transient / Fourier Analysis Setup диалогового окна Analyses Setup (на схеме выберите Design »Simulate» Mixed Sim , затем щелкните Transient / Fourier Analysis запись в списке Analyses / Options ). Этот параметр работает вместе с устройствами .IC (или параметром IC компонентов). При установке этого параметра анализ рабочей точки не выполняется, а указанные напряжения используются в качестве начальных условий для анализа переходных процессов.
- Укажите параметры последовательного сопротивления ваших моделей и увеличьте параметр
GMIN(страница SPICE Options диалогового окна Analyses Setup ) с коэффициентом10. Задайте начальное состояние полупроводниковых приборов, особенно диодов, какOFF.
Устранение неисправностей при анализе развертки постоянного тока
При возникновении проблемы с анализом развертки постоянного тока сначала попробуйте выполнить шаги, перечисленные выше в разделе «Действия по устранению неполадок сходимости».
Если проблемы по-прежнему возникают, попробуйте следующее:
- Измените значение параметра Primary Step на странице DC Sweep Analysis диалогового окна Analyses Setup . Если в модели устройства существуют разрывы (возможно, между линейной областью модели и областью насыщения), увеличение размера шага может позволить моделированию перешагнуть разрыв. С другой стороны, уменьшение шагов позволит моделировать быстрые скачки напряжения при переходе.
- Отключить анализ развертки постоянного тока. Некоторые проблемы (например, гистерезис) не могут быть решены с помощью анализа постоянного тока. В таких случаях более эффективно использовать анализ переходных процессов и увеличивать значения соответствующих источников питания.
Устранение неполадок анализа переходных процессов
Если у вас возникла проблема с анализом переходных процессов, сначала попробуйте выполнить шаги, перечисленные выше в разделе «Действия по устранению проблем сходимости».
Если проблемы по-прежнему возникают, попробуйте следующее.
На странице SPICE Options диалогового окна Analyses Setup (на схеме выберите Design » Simulate » Mixed Sim , затем щелкните запись Advanced Options в Analyses / Список опций ):
- Установите для параметра
RELTOLзначение0,01. При увеличении допуска от значения по умолчанию0,001(точность 0,1%) для схождения решения потребуется меньше итераций, и моделирование будет завершено намного быстрее. - Увеличьте значение параметра
ITL4до100. Это позволит переходному анализу выполнять больше итераций для каждого временного шага, прежде чем отказаться от него. Повышение этого значения может помочь устранитьслишком малых ошибок, улучшая как сходимость, так и скорость моделирования. - Уменьшите точность, увеличив значения
ABSTOLиVNTOL, если уровни тока / напряжения позволяют. Ваша конкретная схема может не требовать разрешения до 1 мкВ или 1 пА.Тем не менее, вы должны позволить, по крайней мере, на порядок ниже минимального ожидаемого уровня напряжения или тока в вашей цепи. - Измените метод интеграции на один из методов Gear . Интеграция шестерен требует более длительного времени моделирования, но обычно более стабильна, чем трапецеидальная. Интеграция шестерен может быть особенно полезна для схем, которые колеблются или имеют пути обратной связи.
Дополнительные возможности:
- Реалистично смоделируйте свою схему.Добавьте реалистичные паразиты, особенно паразитную емкость / переходную емкость. Используйте демпферы RC вокруг диодов. Замените модели устройств на подсхемы, особенно на ВЧ и силовые устройства.
- Увеличьте время нарастания / спада любых источников периодических импульсов в вашей цепи. Даже самые лучшие генераторы импульсов не могут переключаться мгновенно.
% PDF-1.4 % 10431 0 объект > эндобдж xref 10431 209 0000000016 00000 н. 0000010701 00000 п. 0000010946 00000 п. 0000010977 00000 п. 0000011031 00000 п. 0000011091 00000 п. 0000011144 00000 п. 0000011186 00000 п. 0000011224 00000 п. 0000011379 00000 п. 0000011468 00000 п. 0000011553 00000 п. 0000011641 00000 п. 0000011729 00000 п. 0000011817 00000 п. 0000011905 00000 п. 0000011993 00000 п. 0000012081 00000 п. 0000012169 00000 п. 0000012257 00000 п. 0000012345 00000 п. 0000012433 00000 п. 0000012521 00000 п. 0000012609 00000 п. 0000012697 00000 п. 0000012785 00000 п. 0000012873 00000 п. 0000012961 00000 п. 0000013049 00000 п. 0000013137 00000 п. 0000013226 00000 п. 0000013313 00000 п. 0000013400 00000 п. 0000013487 00000 п. 0000013573 00000 п. 0000013659 00000 п. 0000013745 00000 п. 0000013830 00000 п. 0000013915 00000 п. 0000014049 00000 п. 0000014534 00000 п. 0000015188 00000 п. 0000015293 00000 п. 0000016021 00000 п. 0000016474 00000 п. 0000017059 00000 п. 0000017196 00000 п. 0000017338 00000 п. 0000017716 00000 п. 0000022073 00000 п. 0000028144 00000 п. 0000028249 00000 п. 0000066445 00000 п. 0000066696 00000 п. 0000067229 00000 п. 0000067318 00000 п. 0000081175 00000 п. 0000081433 00000 п. 0000081645 00000 п. 0000081941 00000 п. 0000082004 00000 п. 0000082100 00000 п. 0000082194 00000 п. 0000082312 00000 п. 0000082478 00000 п. 0000082668 00000 п. 0000082860 00000 п. 0000083045 00000 п. 0000083186 00000 п. 0000083365 00000 п. 0000083542 00000 п. 0000083659 00000 п. 0000083806 00000 п. 0000083974 00000 п. 0000084085 00000 п. 0000084216 00000 п. 0000084436 00000 п. 0000084609 00000 п. 0000084812 00000 п. 0000084964 00000 п. 0000085081 00000 п. 0000085222 00000 п. 0000085340 00000 п. 0000085506 00000 п. 0000085620 00000 п. 0000085834 00000 п. 0000085948 00000 п. 0000086099 00000 п. 0000086276 00000 п. 0000086448 00000 н. 0000086598 00000 п. 0000086749 00000 п. 0000086929 00000 п. 0000087073 00000 п. 0000087245 00000 п. 0000087393 00000 п. 0000087543 00000 п. 0000087685 00000 п. 0000087837 00000 п. 0000088005 00000 п. 0000088201 00000 п. 0000088387 00000 п. 0000088571 00000 п. 0000088749 00000 п. 0000088915 00000 п. 0000089047 00000 п. 0000089229 00000 п. 0000089385 00000 п. 0000089557 00000 п. 0000089727 00000 н. 0000089891 00000 п. 00000 00000 п. 00000
00000 п. 00000
00000 п.
00000 00000 п.
00000 00000 п.
00000 00000 п.
0000090973 00000 п.
0000091115 00000 п.
0000091273 00000 п.
0000091433 00000 п.
0000091587 00000 п.
0000091729 00000 п.
0000091915 00000 п.
0000092085 00000 п.
0000092259 00000 п.
0000092391 00000 п.
0000092589 00000 п.
0000092753 00000 п.
0000092913 00000 н.
0000093061 00000 п.
0000093273 00000 п.
0000093425 00000 п.
0000093601 00000 п.
0000093763 00000 п.
0000093923 00000 п.
0000094081 00000 п.
0000094235 00000 п.
0000094397 00000 п.
0000094545 00000 п.
0000094757 00000 п.
0000094929 00000 п.
0000095123 00000 п.
0000095303 00000 п.
0000095465 00000 п.
0000095637 00000 п.
0000095775 00000 п.
0000095951 00000 п.
0000096129 00000 п.
0000096303 00000 п.
0000096473 00000 п.
0000096617 00000 п.
0000096781 00000 п.
0000096927 00000 п.
0000097089 00000 п.
0000097231 00000 п.
0000097399 00000 н.
0000097595 00000 п.
0000097773 00000 п.
0000097923 00000 п.
0000098069 00000 п.
0000098243 00000 п.
0000098419 00000 п.
0000098631 00000 п.
0000098815 00000 п.
0000098981 00000 п.
0000099155 00000 п.
0000099353 00000 п.
0000099562 00000 н.
0000099751 00000 п.
0000099954 00000 п.
0000100139 00000 н.
0000100316 00000 н.
0000100489 00000 н.
0000100698 00000 н.
0000100897 00000 н.
0000101080 00000 п.
0000101289 00000 н.
0000101488 00000 н.
0000101671 00000 н.
0000101852 00000 п.
0000102027 00000 н.
0000102212 00000 н.
0000102369 00000 п.
0000102552 00000 н.
0000102739 00000 н.
0000102930 00000 н.
0000103117 00000 п.
0000103298 00000 н.
0000103491 00000 н.
0000103706 00000 н.
0000103907 00000 н.
0000104094 00000 н.
0000104275 00000 п.
0000104458 00000 п.
0000104637 00000 н.
0000104824 00000 н.
0000105001 00000 п.
0000105172 00000 н.
0000105337 00000 н.
0000105558 00000 н.
0000105795 00000 н.
0000106028 00000 н.
0000106225 00000 н.
0000106404 00000 п.
0000106565 00000 н.
0000106748 00000 н.
0000106931 00000 н.
0000004476 00000 н.
трейлер
] / Назад 2396643 >>
startxref
0
%% EOF
10639 0 объект
> поток
h [{| U? 3BZjʣԂN! -Jx (ZCy, bAz'Pʍh, UVdWeWydҖ {̜ {91 Граница логического вывода на основе моделирования
) Механистические модели могут использоваться для прогнозирования поведения систем в различных обстоятельствах.Они охватывают весь диапазон шкал расстояний, с яркими примерами, включая физику элементарных частиц, молекулярную динамику, сворачивание белков, популяционную генетику, нейробиологию, эпидемиологию, экономику, экологию, климатологию, астрофизику и космологию. Выразительность языков программирования облегчает разработку сложных симуляций с высокой точностью, а мощность современных вычислений дает возможность генерировать из них синтетические данные. К сожалению, эти симуляторы плохо подходят для статистических выводов.Источник проблемы состоит в том, что плотность вероятности (или вероятность) для данного наблюдения - важный компонент как частотных, так и байесовских методов вывода - обычно трудноразрешима. Такие модели часто называют неявными моделями и сравнивают с предписанными моделями, в которых вероятность наблюдения может быть вычислена явно (1). Постановка задачи статистического вывода при трудноразрешимых вероятностях была названа выводом без правдоподобия - хотя это немного неправильное название, поскольку обычно пытаются оценить неразрешимую вероятность, поэтому мы считаем, что термин вывод, основанный на моделировании, более уместен.
Сложность вероятности является препятствием для научного прогресса, поскольку статистический вывод является ключевым компонентом научного метода. В областях, где возникла эта преграда, ученые разработали различные специальные или отраслевые методы ее преодоления. В частности, два распространенных традиционных подхода полагаются на то, что ученые используют свое понимание системы для построения мощных сводных статистических данных, а затем сравнивают наблюдаемые данные с смоделированными данными. В первом из них методы оценки плотности используются для аппроксимации распределения сводной статистики по выборкам, сгенерированным симулятором (1).Этот подход был использован для открытия бозона Хиггса в частотной парадигме и проиллюстрирован на рис. 1 E ). В качестве альтернативы метод, известный как приближенное байесовское вычисление (ABC) (2, 3), сравнивает наблюдаемые и смоделированные данные на основе некоторой меры расстояния, включающей сводную статистику. ABC широко используется в популяционной биологии, вычислительной нейробиологии и космологии и изображена на рис. 1 A . Оба метода обслуживают широкий и разнообразный сегмент научного сообщества.
В последнее время набор инструментов для вывода на основе моделирования пережил ускоренное расширение. Вообще говоря, три силы придают этой области новый импульс. Во-первых, наблюдается значительный перекрестный обмен мнениями между теми, кто изучает логический вывод на основе моделирования, и теми, кто изучает вероятностные модели в машинном обучении (ML) (4), а впечатляющий рост возможностей машинного обучения позволяет использовать новые подходы. Во-вторых, активное обучение - идея постоянного использования приобретенных знаний для управления симулятором - признается ключевой идеей для повышения эффективности выборки различных методов вывода.Третье направление исследований перестало рассматривать симулятор как черный ящик и сосредоточилось на интеграции, которая позволяет механизму вывода напрямую подключаться к внутренним деталям симулятора.
На фоне продолжающейся революции ситуация с логическим выводом на основе моделирования быстро меняется. В этом обзоре мы стремимся предоставить читателю общий обзор основных идей, лежащих в основе как старых, так и новых методов вывода. Вместо того, чтобы обсуждать алгоритмы в технических деталях, мы сосредотачиваемся на текущих границах исследований и комментируем некоторые текущие разработки, которые мы считаем особенно интересными.
Вывод на основе моделирования
Симуляторы.
Статистический вывод выполняется в контексте статистической модели, а при выводе на основе моделирования статистическая модель определяется самим имитатором. Для целей данной статьи имитатор - это компьютерная программа, которая принимает на вход вектор параметров θ, выбирает серию внутренних состояний или скрытых переменных zi∼pi (zi | θ, z • Параметры θ описывают лежащую в основе механистическую модель и, таким образом, влияют на вероятности перехода pi (zi | θ, z
• Скрытые переменные z, которые появляются в процессе генерации данных, могут прямо или косвенно соответствовать физически значимому состоянию системы, но обычно это состояние ненаблюдаемо на практике. Структура скрытого пространства существенно различается между симуляторами. Скрытые переменные могут быть непрерывными или дискретными, а размерность скрытого пространства может быть фиксированной или может изменяться в зависимости от потока управления симулятора. Моделирование может свободно комбинировать детерминированные и стохастические шаги.Детерминированные компоненты симулятора могут быть дифференцируемыми или могут включать в себя элементы прерывистого потока управления. На практике некоторые симуляторы могут обеспечить удобный доступ к скрытым переменным, в то время как другие фактически являются черными ящиками. Любой симулятор может комбинировать эти различные аспекты практически любым способом.
• Наконец, выходные данные x соответствуют наблюдениям. Они могут варьироваться от нескольких неструктурированных чисел до многомерных и высокоструктурированных данных, таких как изображения или геопространственная информация.
Например, процессы физики элементарных частиц часто зависят только от небольшого числа представляющих интерес параметров, таких как массы частиц или силы связи. Скрытый процесс сочетает в себе высокоэнергетическое взаимодействие, строго описываемое квантовой теорией поля, с прохождением образующихся частиц через невероятно сложный детектор, наиболее точно моделируемый стохастическим моделированием с миллиардами скрытых переменных. Эпидемиологическое моделирование может быть основано на сетевой структуре с геопространственными свойствами, а скрытый процесс состоит из множества повторяющихся структурно идентичных стохастических временных шагов.Напротив, космологическое моделирование эволюции Вселенной может состоять из сильно структурированного стохастического начального состояния, за которым следует плавная детерминированная временная эволюция.
Эти различия приводят к отсутствию универсального метода вывода. В этом обзоре мы стремимся прояснить соображения, необходимые для выбора наиболее подходящего подхода к данной проблеме.
Вывод.
Задачи научного вывода различаются в зависимости от того, что делается: учитывая наблюдаемые данные x, является ли цель вывести входные параметры θ или скрытые переменные z, или и то, и другое? Мы сосредоточимся на общей проблеме вывода θ в параметрической установке, мы прокомментируем методы, которые позволяют вывод по z, и мы не будем сосредотачиваться на непараметрических обратных задачах.(x) или расширен, чтобы включить вероятностное понятие неопределенности. В случае частотного анализа доверительные наборы часто формируются из тестов инвертирования гипотез, основанных на статистике теста отношения правдоподобия. В байесовском выводе цель обычно состоит в том, чтобы вычислить апостериорное значение p (θ | x) = p (x | θ) p (θ) / ∫ dθ′p (x | θ ′) p (θ ′) для наблюдаемых данных x и заданный априор p (θ). В обоих случаях функция правдоподобия p (x | θ) является ключевым ингредиентом.
Основная проблема для задач вывода на основе моделирования состоит в том, что функция правдоподобия p (x | θ), неявно определенная симулятором, обычно не поддается отслеживанию, поскольку она соответствует интегралу по всем возможным траекториям через скрытое пространство (т.е., все возможные следы исполнения тренажера). То есть p (x | θ) = ∫ dz p (x, z | θ), [1] где p (x, z | θ) - совместная плотность вероятности данных x и скрытых переменных z. Для реальных симуляторов с большими скрытыми пространствами явно невозможно вычислить этот интеграл в явном виде. Поскольку функция правдоподобия является центральным компонентом как частотного, так и байесовского вывода, это является серьезной проблемой для вывода во многих областях. В этой статье рассматриваются основанные на моделировании или вероятностные методы вывода, которые позволяют делать частотный или байесовский вывод, несмотря на эту сложность.Эти методы можно рассматривать как специализацию количественной оценки обратной неопределенности (UQ) параметров модели в ситуациях с точными стохастическими симуляторами.
На практике важным различием является различие между выводом, основанным на одном наблюдении, и выводом, основанным на нескольких независимых и одинаково распределенных (i.i.d.) наблюдениях. Во втором случае вероятность разлагается на отдельные составляющие вероятности для каждого i.i.d. наблюдение, поскольку p (x | θ) = ∏ipindividual (xi | θ).Например, данные временных рядов обычно не являются i.i.d. и его следует рассматривать как единичное наблюдение большой размерности, тогда как анализ данных о столкновениях при поиске бозона Хиггса представляет собой набор данных с множеством i.i.d. измерения. Это различие важно, когда речь идет о вычислительных затратах на метод вывода, так как вывод в i.i.d. Случай потребует многократных повторных оценок индивидуального индивидуума правдоподобия (xi | θ).
Традиционные методы.
Проблема вывода без поддающихся обработке вероятностей не нова, и для ее решения были разработаны два основных подхода.Пожалуй, наиболее известным является ABC (2, 3). До недавнего времени было установлено, что термины «вывод без правдоподобия» и «ABC» часто использовались как синонимы. В простейшей форме отклонения ABC параметры θ берутся из предыдущего, симулятор запускается с этими значениями для выборки xsim∼p (⋅ | θ), а θ сохраняется в качестве апостериорной выборки, если моделируемые данные достаточно близки к наблюдаемым данным. По сути, вероятность аппроксимируется вероятностью того, что выполняется условие ρ (xsim, xobs) <ρ, где ρ - некоторая мера расстояния, а ϵ - допуск.Принятые образцы затем следуют приблизительной версии апостериорного исследования. Мы показываем схематический рабочий процесс этого алгоритма на рис. 1 A (для более сложного алгоритма Монте-Карло цепи Маркова с функцией предложения).
В пределе ϵ → 0 вывод с помощью ABC становится точным, но для непрерывных данных вероятность принятия равна нулю. На практике малые значения ϵ требуют невероятно большого количества симуляций. Для больших эффективность выборки увеличивается за счет качества вывода.Точно так же эффективность выборки ABC плохо масштабируется для данных большой размерности x. Поскольку данные немедленно влияют на процесс отклонения (и в более продвинутых алгоритмах ABC на распределение предложений), вывод для новых наблюдений требует повторения всего алгоритма вывода. Таким образом, ABC лучше всего подходит для случая одного наблюдения или, самое большее, нескольких i.i.d. точки данных. Не имея места, чтобы отдать должное обширной литературе ABC, мы отсылаем читателя к обзору методов ABC, см. Исх. 5 и выделите комбинацию с цепью Маркова Монте-Карло (MCMC) (6) и последовательным Монте-Карло (SMC) (7, 8).
Второй классический подход к выводу на основе моделирования основан на создании модели правдоподобия путем оценки распределения смоделированных данных с помощью гистограмм или оценки плотности ядра (1). Тогда частотный и байесовский вывод происходит так, как если бы вероятность была поддающейся обработке. Мы схематически изображаем этот алгоритм на рис. 1 E (заменяя зеленый этап обучения классическим методом оценки плотности). Этот подход имеет достаточно сходства с ABC, чтобы авторы ссылки назвали его «приближенным частотным вычислением».9. Одним из преимуществ перед ABC является амортизация: после предварительных затрат на вычисления на этапе моделирования и оценки плотности новые точки данных могут быть эффективно оценены. На рис. 1 E это изображено синим полем «данных», вводимым только на этапе вывода и не влияющим на этап моделирования. Это свойство делает вывод на основе оценки плотности особенно подходящим для задач со многими i.i.d. наблюдения, что является основной причиной его широкого использования в измерениях физики элементарных частиц.
Оба традиционных подхода страдают от проклятия размерности: в худшем случае необходимое количество симуляций увеличивается экспоненциально с размерностью данных x. Следовательно, оба подхода полагаются на сводную статистику y (x) низкой размерности, а качество вывода зависит от того, насколько хорошо эти сводки сохраняют информацию о параметрах θ. Традиционно разработка мощной сводной статистики была задачей эксперта в предметной области, и сводная статистика предписывалась до вывода.
Границы вывода на основе моделирования.
Эти традиционные методы вывода, основанные на моделировании, уже много лет играют ключевую роль в нескольких областях. Однако они страдают недостатками в трех важных аспектах:
• Эффективность выборки: количество смоделированных выборок, необходимое для обеспечения хорошей оценки вероятности или апостериорной вероятности, может быть чрезмерно дорогим.
• Качество вывода: при сведении данных к сводной статистике низкого измерения неизменно отбрасывается некоторая информация в данных о θ, что приводит к потере статистической мощности.Большие значения параметра ϵ в ABC или параметра полосы пропускания для оценки плотности ядра приводят к плохой аппроксимации истинного правдоподобия. Оба снижают общее качество вывода.
• Амортизация: Выполнение вывода с помощью ABC для нового набора наблюдаемых данных требует повторения большинства шагов цепочки вывода, в частности, если распределение предложения зависит от наблюдаемых данных. Метод плохо масштабируется при применении к большому количеству наблюдений. С другой стороны, вывод, основанный на оценке плотности, амортизируется: дорогостоящие в вычислительном отношении шаги не должны повторяться для новых наблюдений.Это особенно желательно в случае с i.i.d. наблюдения.
В последние годы стали доступны новые возможности, позволяющие улучшить все три этих аспекта. Мы условно сгруппируем их по трем основным направлениям развития:
1) Революция машинного обучения позволяет нам работать с данными более высокой размерности, что может улучшить качество вывода. Методы вывода, основанные на суррогатах нейронных сетей, напрямую выигрывают от впечатляющих темпов прогресса в глубоком обучении.
2) Методы активного обучения могут систематически повышать эффективность выборки, позволяя нам использовать более дорогие в вычислительном отношении симуляторы.
3) Глубокая интеграция автоматического дифференцирования и вероятностного программирования в код моделирования, а также дополнение обучающих данных информацией, которая может быть извлечена из симулятора, меняет способ обработки симулятора в выводе: больше не является черным ящиком, но подвергается процессу вывода.
Революция в машинном обучении.
За последнее десятилетие методы машинного обучения, в частности глубокие нейронные сети, превратились в универсальные, мощные и популярные инструменты для решения множества задач (10). Первоначально нейронные сети продемонстрировали прорыв в задачах контролируемого обучения, таких как классификация и регрессия. Их можно легко составлять для решения задач более высокого уровня, подстраиваясь под задачи с иерархической или композиционной структурой. Были разработаны архитектуры, адаптированные к различным структурам данных, включая плотные или полностью связанные сети, нацеленные на неструктурированные данные, сверточные нейронные сети, которые используют пространственную структуру, например, в данных изображения, рекуррентные нейронные сети для последовательностей переменной длины и нейронные сети на графах для графов. структурированные данные.Выбор архитектуры, хорошо подходящей для конкретной структуры данных, является примером индуктивного смещения, которое в более общем плане относится к предположениям, присущим алгоритму обучения, независимому от данных. Индуктивная предвзятость - одна из ключевых составляющих наиболее успешных приложений глубокого обучения, хотя трудно точно охарактеризовать ее роль.
Одной из областей, где активно развиваются нейронные сети, является оценка плотности в больших измерениях: для заданного набора точек {x} ∼p (x) цель состоит в том, чтобы оценить плотность вероятности p (x).Поскольку явных ярлыков нет, это обычно считается задачей обучения без учителя. Мы уже обсуждали, что классические методы, основанные, например, на гистограммах или оценке плотности ядра, плохо масштабируются для данных большой размерности. В этом режиме все более популярными становятся методы оценки плотности на основе нейронных сетей. Одним из классов этих методов оценки нейронной плотности являются нормализующие потоки (11⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓ – 26), в которых переменные, описываемые простым базовым распределением p (u), например многомерным гауссовским, являются преобразованный через параметризованное обратимое преобразование x = gϕ (u), которое имеет уступчивый якобиан.Тогда целевая плотность pg (x) определяется формулой замены переменных как произведение базовой плотности и определителя якобиана преобразования. Несколько таких шагов могут быть объединены, при этом плотность вероятности «течет» через последовательные преобразования переменных. Параметры ϕ преобразований обучаются путем максимизации правдоподобия наблюдаемых данных в рамках модели pg (xobs), что приводит к плотности модели, которая приближается к истинной, неизвестной плотности p (x). Помимо регулируемой плотности, можно генерировать данные из модели, извлекая скрытые переменные u из базового распределения и применяя преобразования потока.Оценщики нейронной плотности были обобщены для моделирования зависимости от дополнительных входных данных, то есть для моделирования условной плотности, такой как вероятность p (x | θ) или апостериорная p (θ | x).
Генеративные состязательные сети (GAN) - это альтернативный тип генеративной модели, основанный на нейронных сетях. В отличие от нормализующих потоков преобразование, реализуемое генератором, не ограничивается обратимостью. Хотя это обеспечивает большую выразительность, плотность, определяемая генератором, непреодолима.Поскольку максимальная вероятность не является возможной целью обучения, генератор настраивается против злоумышленника, роль которого заключается в том, чтобы отличать сгенерированные данные от целевого распределения. Позже мы обсудим, как ту же идею можно использовать для вывода на основе моделирования, используя идею, известную как «трюк отношения правдоподобия».
Активное обучение.
Простая, но очень эффективная идея - запустить симулятор в точках параметров θ, которые, как ожидается, максимально увеличат наши знания.Это можно делать итеративно, так что после каждого моделирования информация, полученная в результате всех предыдущих прогонов, используется для определения того, какую точку параметра следует использовать в следующий раз. Есть несколько технических реализаций идеи активного обучения. Он обычно применяется в байесовской настройке, где апостериорные данные могут постоянно обновляться и использоваться для управления предложенным распределением параметров симулятора (27⇓⇓⇓⇓⇓ – 33). Но это также хорошо применимо к эффективному вычислению частотных доверительных наборов (34⇓ – 36).Даже простая реализация может привести к существенному повышению эффективности выборки.
Подобные идеи обсуждаются в контексте принятия решений, экспериментального проектирования и обучения с подкреплением, и мы ожидаем дальнейших улучшений в алгоритмах вывода от перекрестного опыления между этими областями. Например, вопрос, который время от времени обсуждается в контексте обучения с подкреплением (37, 38) или байесовской оптимизации (39), но еще не применялся к параметрам без вероятности, заключается в том, как использовать симуляторы множественности, предлагающие несколько уровни точности или приближения.
Интеграция и расширение.
Как машинное обучение, так и активное обучение могут существенно улучшить качество вывода и эффективность выборки по сравнению с классическими методами. Однако в целом они не меняют кардинально базовый подход к выводу на основе моделирования: они по-прежнему рассматривают симулятор как генеративный черный ящик, который принимает параметры в качестве входных данных и предоставляет данные в качестве выходных, с четким разделением между имитатором и механизмом логического вывода. Третье направление исследований - это изменение этой точки зрения путем открытия черного ящика и более тесной интеграции вывода и моделирования.
Одним из примеров этого сдвига является парадигма вероятностного программирования. Гордон и др. (40) описывают вероятностные программы как обычные функциональные или императивные программы с двумя добавленными конструкциями: 1) способность извлекать значения случайным образом из распределений и 2) способность обусловливать значения переменных в программе посредством наблюдений. Мы уже описали симуляторы как вероятностные программы, ориентированные на первую конструкцию, которая не требует открытия черного ящика. Однако обусловливание наблюдений требует более глубокой интеграции, поскольку включает в себя контроль случайности в процессе генерации.Этот подход абстрагирует возможности, необходимые для реализации фильтров частиц и SMC (41). Раньше для этого требовалось писать программу на специальном языке; однако недавние работы позволяют добавлять эти возможности к существующим симуляторам с минимальными изменениями в их кодовой базе (42). В конечном итоге вероятностное программирование направлено на предоставление инструментов для вывода невероятно сложного пространства всех следов выполнения симулятора, обусловленного наблюдением.
Дополнительным развитием является наблюдение, что дополнительная информация, характеризующая процесс генерации скрытых данных, может быть извлечена из симулятора и использоваться для увеличения данных, используемых для обучения суррогатов.Тем, кто разрабатывает алгоритмы вывода, и тем, кто знаком с деталями симулятора, следует подумать о том, являются ли, помимо единственной возможности выборки x∼p (x | θ), следующими величинами хорошо определенными и управляемыми:
1) p (x | z, θ)
2) t (x, z | θ) ≡∇θlogp (x, z | θ)
3) ∇zlogp (x, z | θ)
4) r (x, z | θ, θ ′) ≡p (x, z | θ) / p (x, z | θ ′)
5) ∇θ (x , z)
6) ∇zx.
Эти величины затем можно использовать для увеличения обычного вывода x симулятора и использовать в целях обучения с учителем, что может значительно повысить эффективность выборки для суррогатного обучения (43⇓ – 45), как мы подробно рассмотрим позже.
Многие из приведенных выше величин включают производные, которые теперь можно эффективно вычислить с помощью автоматического дифференцирования (часто называемого просто автодифференцированием) (46). Autodiff - это семейство методов, аналогичных алгоритму обратного распространения ошибки, но более общему, чем алгоритм обратного распространения ошибки, который повсеместно используется в глубоком обучении. Автоматическое дифференцирование, как и вероятностное программирование, включает нестандартные интерпретации кода моделирования и было разработано небольшой, но устоявшейся областью компьютерных наук.В последние годы несколько исследователей высказались за то, чтобы глубокое обучение лучше описывать как дифференциальное программирование (47, 48). С этой точки зрения включение autodiff в существующие коды моделирования - более прямой способ использовать достижения в области глубокого обучения, чем попытки включить знания предметной области в совершенно чужеродный субстрат, такой как глубокая нейронная сеть.
Для извлечения необходимой информации из симулятора снова требуется глубокая интеграция в коде. В то время как технологии для включения парадигмы вероятностного программирования в существующие кодовые базы только появляются, разработка инструментов для включения autodiff в наиболее часто используемых языках научного программирования далеко продвинулась.Мы подчеркиваем, что две из перечисленных выше величин (величины 2 и 3) включают как автодифференциальное, так и вероятностное программирование. Интеграция логического вывода и моделирования, а также идея дополнения обучающих данных дополнительными величинами потенциально могут изменить то, как мы думаем о выводе на основе моделирования. В частности, эта перспектива может повлиять на способ разработки кодов моделирования для обеспечения этих новых возможностей.
Рабочие процессы для вывода на основе моделирования
Этот широкий спектр возможностей можно комбинировать в различных рабочих процессах вывода.В качестве ориентира для этого множества различных рабочих процессов давайте сначала обсудим общие строительные блоки и различные подходы, которые можно использовать в каждом из этих компонентов. На рис. 1 и в следующих разделах мы затем объединим эти блоки в разные алгоритмы вывода.
Неотъемлемой частью всех методов вывода является запуск симулятора, представленного в виде желтого пятиугольника на рис. 1. Параметры, при которых запускается симулятор, взяты из некоторого распределения предложений, которое может зависеть или не зависеть от предыдущего в Байесовская настройка, которую можно выбрать статически или итеративно с помощью активного метода обучения.Затем потенциально многомерные выходные данные симулятора могут использоваться непосредственно в качестве входных данных для метода вывода или сводиться к сводной статистике низкой размерности.
Методы вывода можно в целом разделить на те, которые, как и ABC, используют сам симулятор во время вывода, и методы, которые создают суррогатную модель и используют ее для вывода. В первом случае выходные данные симулятора напрямую сравниваются с данными (Рис. 1 A – D ). В последнем случае выходные данные симулятора используются в качестве обучающих данных для этапа оценки или машинного обучения, что показано зелеными прямоугольниками на рис.1 E - H . Полученные суррогатные модели, показанные в виде красных шестиугольников, затем используются для вывода.
Алгоритмы решают проблему неразрешимости истинного правдоподобия по-разному: одни методы конструируют поддающийся обработке суррогат для функции правдоподобия, а другие - для функции отношения правдоподобия, причем оба метода упрощают частотный вывод. В других методах функция правдоподобия никогда не появляется явно, например, когда она неявно заменяется вероятностью отклонения.
Конечная цель байесовского вывода - апостериорная. Методы различаются тем, предоставляют ли они доступ к выборкам точек параметров, выбранных из апостериорной, например, из MCMC или ABC, или управляемой функции, которая аппроксимирует апостериорную функцию. Точно так же некоторые методы требуют указания количества, которое должно быть выведено на ранней стадии рабочего процесса, в то время как другие позволяют отложить это решение.
Использование симулятора непосредственно во время вывода.
Давайте теперь обсудим, как эти блоки и вычислительные возможности могут быть объединены в методы вывода, начиная с тех, которые, как и ABC, используют симулятор непосредственно во время вывода.Набросок некоторых из этих алгоритмов представлен на рис. 1 A – D .
Причина низкой эффективности выборки исходного алгоритма отклонения ABC заключается в том, что симулятор запускается в точках параметров, взятых из предыдущего, которые могут иметь большую массу в регионах, которые сильно не согласуются с наблюдаемыми данными. Были предложены различные алгоритмы, которые вместо этого запускают симулятор в точках параметров, которые, как ожидается, улучшат знания в наибольшей степени (27⇓⇓⇓ – 31). По сравнению с обычным ABC, эти методы повышают эффективность выборки, хотя они по-прежнему требуют выбора сводной статистики, меры расстояния ρ и допуска.
В случае, когда последний этап симулятора управляем или симулятор дифференцируем (соответственно, свойства 1 и 6 из списка в Integration and Augmentation ), асимптотически точный байесовский вывод возможен (43), не полагаясь на допуск на расстояние или сводная статистика, устраняющая основные ограничения ABC с точки зрения качества вывода.
Парадигма вероятностного программирования представляет собой более фундаментальное изменение способа выполнения вывода.Во-первых, симулятор должен быть написан на вероятностном языке программирования, хотя недавние работы позволяют добавлять эти возможности к существующим симуляторам с минимальными изменениями в их кодовой базе (42). Кроме того, вероятностное программирование требует либо поддающейся обработке правдоподобия для последнего шага p (x | z, θ) (величина 1), либо введения сравнения в стиле ABC. Когда эти критерии удовлетворяются, существует несколько алгоритмов вывода, которые могут извлекать выборки из апостериорных p (θ, z | x) входных параметров θ и скрытых переменных z с учетом некоторых наблюдаемых данных x.Эти методы основаны либо на MCMC (рис. 1 C ), либо на обучении нейронной сети для предоставления распределений предложений (49), как показано на рис. 1 D . Ключевое отличие от ABC заключается в том, что механизм вывода контролирует все этапы выполнения программы и может смещать каждый отбор случайных скрытых переменных, чтобы моделирование с большей вероятностью соответствовало наблюдаемым данным, повышая эффективность выборки.
Сильной стороной этих алгоритмов является то, что они позволяют нам вывести не только входные параметры в симулятор, но и весь скрытый процесс, ведущий к конкретному наблюдению.Это позволяет нам отвечать на совершенно разные вопросы о научных процессах, добавляя особую физическую интерпретируемость, которой не обладают методы, основанные на суррогатах. В то время как стандартные алгоритмы ABC в принципе позволяют делать выводы о z, вероятностное программирование решает эту задачу более эффективно.
Суррогатные модели.
Ключевым недостатком использования симулятора непосредственно во время вывода является отсутствие амортизации. Когда становятся доступными новые наблюдаемые данные, необходимо повторить всю цепочку вывода.При обучении послушного суррогата или эмулятора для симулятора вывод амортизируется: после предварительного моделирования и фазы обучения новые данные могут быть оценены очень эффективно. Этот подход особенно хорошо масштабируется для данных, состоящих из множества i.i.d. наблюдения. Как обсуждалось в Традиционные методы , это не новая идея, и хорошо зарекомендовавшие себя методы используют классические методы оценки плотности для создания суррогатной модели для функции правдоподобия. Но новые вычислительные возможности, обсуждаемые в Simulation-Based Inference , придали новый импульс этому классу методов вывода, некоторые из которых визуализированы на рис.1 E – H .
Мощный вероятностный подход заключается в обучении нейронных средств оценки условной плотности, таких как нормализация потоков, в качестве суррогата для симулятора. Условная плотность может быть определена в двух направлениях: сеть может изучать апостериорное значение p (θ | x) (32, 50⇓⇓⇓ – 54) или вероятность p (x | θ) (33, 55⇓ – 57). . Мы показываем эти три метода на рис. 1 E и F ; Обратите внимание, что алгоритм суррогата правдоподобия структурно идентичен классическому подходу, основанному на оценке плотности, но использует более мощные методы оценки плотности.
Соответственно, нейронные сети можно обучить изучать функцию отношения правдоподобия p (x | θ0) / p (x | θ1) или p (x | θ0) / p (x), где в последнем случае знаменатель дается маржинальной моделью, интегрированной по предложению или предшествующему (4, 58–65). Набросок этого подхода представлен на рис. 1 G . Ключевая идея тесно связана с дискриминаторной сетью в GAN, упомянутой выше: классификатор обучается с использованием контролируемого обучения для различения двух наборов данных, хотя в этом случае оба набора поступают из симулятора и генерируются для разных точек параметров θ0 и θ1.Выходную функцию классификатора можно преобразовать в приближение отношения правдоподобия между θ0 и θ1! Это проявление леммы Неймана – Пирсона в условиях машинного обучения часто называют трюком отношения правдоподобия.
Эти три подхода, основанные на суррогатах, амортизируются: после предварительного моделирования и фазы обучения суррогаты могут быть эффективно оценены для произвольных данных и точек параметров. Они требуют предварительной спецификации интересующих параметров, а затем сеть неявно уступает место всем остальным (скрытым) переменным в симуляторе.Все три класса алгоритмов могут использовать элементы активного обучения, такие как итеративно обновляемое распределение предложений, чтобы направлять параметры симулятора θ к соответствующей области параметров, повышая эффективность выборки. Использование нейронных сетей устраняет необходимость в сводной статистике низкого уровня, оставляя на усмотрение используемой модели изучение структур в данных высокой размерности и потенциально улучшающее качество вывода.
Несмотря на эти фундаментальные сходства, есть некоторые различия между имитацией вероятности, отношением правдоподобия и апостериорной вероятностью.Непосредственное изучение апостериорного вывода обеспечивает основную целевую величину в байесовском выводе, но вызывает априорную зависимость на каждом этапе метода вывода. Изучение правдоподобия или отношения правдоподобия позволяет делать частотный вывод или сравнения моделей, хотя для байесовского вывода необходим дополнительный шаг MCMC или количество 6 для генерации выборок из апостериорного анализа. Априорная независимость оценок правдоподобия или отношения правдоподобия также приводит к дополнительной гибкости для изменения априорной оценки во время вывода.Преимущество обучения генеративной модели для аппроксимации вероятности или апостериорной вероятности по сравнению с обучением функции отношения правдоподобия заключается в дополнительной функциональности возможности выборки из суррогатной модели. С другой стороны, изучение вероятности или апостериорного обучения является проблемой обучения без учителя, тогда как оценка отношения правдоподобия с помощью классификатора является примером обучения с учителем и часто является более простой задачей. Поскольку для цели вывода более высокого уровня вероятность и отношение правдоподобия могут использоваться взаимозаменяемо, изучение суррогата для функции отношения правдоподобия часто может быть более эффективным.
Другая стратегия, которая позволяет нам использовать контролируемое обучение, основана на извлечении дополнительных величин из симулятора, которые характеризуют вероятность скрытого процесса (например, количества 2 и 4 из списка в Integration and Augmentation ). Эту дополнительную информацию можно использовать для пополнения обучающих данных для суррогатных моделей. Результирующая задача контролируемого обучения часто может быть решена более эффективно, в конечном итоге повышая эффективность выборки в задаче вывода (9, 44, 45, 66).
Подходы, основанные на суррогатах, выигрывают от введения подходящего индуктивного смещения для данной проблемы. Широко признано, что сетевая архитектура нейронного суррогата должна выбираться в соответствии со структурой данных (например, изображениями, последовательностями или графиками). Другой, потенциально более значимый способ навязать индуктивное смещение состоит в том, чтобы суррогатная модель отражала причинную структуру симулятора. Определение соответствующих структур вручную и проектирование соответствующих суррогатных архитектур очень сильно зависит от предметной области, хотя, как было показано, улучшает производительность при решении некоторых проблем (67–69).Недавно были предприняты попытки автоматизировать процесс создания суррогатов, имитирующих моделирование (70). Заглядывая дальше, мы хотели бы изучить суррогаты, которые отражают причинную структуру грубой системы. Если это возможно, это позволит суррогату моделировать только соответствующие степени свободы для явлений, которые возникают из лежащей в основе механистической модели.
Предварительная и постобработка.
Существует ряд дополнительных шагов, которые могут окружать эти основные алгоритмы вывода, либо в форме шагов предварительной обработки, которые предшествуют основному этапу вывода, либо в виде дожигания после основного шага вывода.
Один из этапов предварительной обработки - изучение мощных сводок y (x). Из-за проклятия размерности и ABC, и классические методы вывода, основанные на оценке плотности, требуют сжатия данных в сводную статистику низкого уровня. Обычно они назначаются (т. Е. Выбираются вручную учеными в предметной области на основе их интуиции и знания проблемы), но итоговые сводки обычно теряют некоторую информацию по сравнению с исходными данными. Минимально инвазивное расширение этих алгоритмов состоит в том, чтобы сначала изучить сводную статистику, которая имеет определенные свойства оптимальности, перед запуском стандартного алгоритма вывода, такого как ABC.Мы набросали этот подход на рис. 1 B для ABC, но он в равной степени применим к выводу, основанному на оценке плотности.
Оценка t (x | θ) ≡∇θp (x | θ), градиент логарифмического (маргинального) правдоподобия по отношению к интересующим параметрам, определяет такой вектор оптимальной суммарной статистики: В окрестности θ компоненты оценки представляют собой достаточную статистику, и их можно использовать для вывода без потери информации. Как и вероятность, оценка сама по себе, как правило, не поддается обработке, но ее можно оценить на основе величины 5 и экспоненциального семейного приближения (71, 72).Если доступно количество 2, вместо этого можно использовать расширенные данные, извлеченные из симулятора, для обучения нейронной сети для оценки оценки (44), не требуя такого приближения. Полученные сводки также можно сделать устойчивыми по отношению к мешающим параметрам (73, 74).
Даже если нет необходимости сводить данные к сводной статистике низкого уровня, в некоторых полях измеренные необработанные или «низкоуровневые» данные могут быть очень многомерными. В таком случае обычной практикой является их сжатие до более управляемого набора «высокоуровневых» функций умеренной размерности и использование этих сжатых данных в качестве входных данных для рабочего процесса вывода.
Компиляция вывода (49) - это этап предварительной обработки для алгоритмов вероятностного программирования, показанный на рис. 1 D . Первоначальные прогоны симулятора используются для обучения нейронной сети, используемой для последовательной выборки по важности как θ, так и z.
После завершения основного рабочего процесса вывода возникает важный вопрос, являются ли результаты надежными: можно ли доверять результату при наличии недостатков, таких как ограниченный размер выборки, недостаточная пропускная способность сети или неэффективная оптимизация?
Одно из решений - откалибровать результаты логического вывода.Используя способность симулятора генерировать данные для любой точки параметра, мы можем использовать параметрический подход начальной загрузки для расчета распределения любой величины, участвующей в рабочем процессе вывода. Эти распределения можно использовать для калибровки процедуры вывода, чтобы обеспечить наборы достоверности и апостериорные данные с надлежащим охватом и достоверностью (9, 60). Хотя такие процедуры в принципе возможны, они могут потребовать большого количества симуляций. Другие диагностические инструменты, которые могут применяться в конце этапа вывода, включают обучающие классификаторы для различения данных суррогатной модели и истинного симулятора (60), проверки самосогласованности (9, 60), методы ансамбля и сравнение распределений сети. вывод против известных асимптотических свойств (75⇓ – 77).Некоторые из этих методов могут использоваться для оценки неопределенности, хотя статистическая интерпретация таких планок погрешностей не всегда очевидна.
Ни одна из этих диагностических программ не решает проблемы, возникающие, если модель указана неправильно, а симулятор не является точным описанием изучаемой системы. Ошибочная спецификация модели - это проблема, которая в равной степени затрудняет вывод как предписанных, так и неявных моделей. Обычно это решается путем расширения модели для большей гибкости и введения дополнительных мешающих параметров.
Рекомендации.
Соображения, необходимые для выбора, какой из описанных выше подходов лучше всего подходит для данной проблемы, будут включать цели вывода, размерность параметров модели, скрытые переменные и данные; доступна ли хорошая сводная статистика; внутреннее устройство тренажера; вычислительная стоимость тренажера; уровень контроля за запуском симулятора; и является ли имитатор «черным ящиком», и можно ли извлечь из него какие-либо величины, обсуждаемые в документе «Интеграция и расширение» .Тем не менее, мы считаем, что существующие исследования позволяют нам дать несколько общих рекомендаций.
Во-первых, если доступны какие-либо из величин, обсуждаемых в Границы вывода на основе моделирования , их следует использовать. Доступны мощные алгоритмы для случая с дифференцируемыми симуляторами (43), для симуляторов, для которых доступна совместная вероятность данных и скрытых переменных (44), и для симуляторов, явно написанных как вероятностная модель в рамках вероятностного программирования (78).Вероятностное программирование также является наиболее универсальным подходом, когда целью является не только вывод по параметрам θ, но также вывод по скрытым переменным z.
Если установлены мощные сводные низкоразмерные статистические данные, традиционные методы все равно могут предложить приемлемую производительность. Однако в большинстве случаев мы рекомендуем попробовать методы, основанные на обучении суррогата нейронной сети для вероятности (33, 56) или отношения правдоподобия (60, 62, 64). Если создание синтетических данных из суррогата не важно, изучение отношения правдоподобия, а не правдоподобия, позволяет нам использовать мощные контролируемые методы обучения.
Наконец, методы активного обучения могут повысить эффективность выборки для всех методов вывода. Существует компромисс между активным обучением, которое адаптирует эффективность к конкретному наблюдаемому набору данных, и амортизацией, которая выигрывает от суррогатов, которые не зависят от наблюдаемых данных. Хороший компромисс здесь будет зависеть от количества наблюдений и резкости заднего обзора по сравнению с предыдущим.
LTspice: ускорение моделирования
LTspice разработан с нуля для быстрого моделирования схем, но в некоторых моделированиях есть запас для увеличения скорости.Обратите внимание, что при использовании описанных здесь методов возможны компромиссы в отношении точности. Дополнительные сведения о любом из этих подходов см. В файле справки LTspice (F1). Чтобы измерить влияние ваших изменений, просмотрите время моделирования в журнале ошибок LTspice (Ctrl + L).
Уменьшите время, необходимое для моделирования импульсного источника питания (SMPS), сократив линейное изменение напряжения на выходе, изменив значение конденсатора плавного пуска. Перед тем как сделать это, убедитесь, что вы хорошо разбираетесь в пусковых характеристиках источника питания.Затем уменьшите емкость конденсатора плавного пуска - используя 0,001 мкФ вместо значения по умолчанию 0,1 мкФ - для быстрого перехода к желаемому выходному напряжению.
Обратите внимание, что конденсатор плавного пуска не следует уменьшать до точки, при которой возрастающий выходной сигнал позволяет выводу V C / I TH выходить за пределы своей номинальной контрольной точки и спускаться дальше, чтобы остановить выброс.
Задержка приложения нагрузки к источнику питания
Еще один эффективный метод ускорения моделирования SMPS - задержка приложения нагрузки с помощью переключателя, управляемого напряжением (SW).При использовании переключателя, который включает основную нагрузку, когда выходное напряжение приближается к норме (или в известное время), вся выходная энергия SMPS идет на зарядку больших выходных конденсаторов до включения нагрузки. Пусковое сопротивление и сопротивление основной нагрузки также могут быть заключены в Ron и Roff из описания модели SW, а не с использованием отдельных резисторов.
Более простой подход может быть достигнут с использованием токовой нагрузки, сконфигурированной с импульсной функцией.
Установите начальные условия
Аналогичным образом может быть эффективным использование.ic spice, чтобы установить начальные условия для выбранных узлов. Например, укажите начальное напряжение на выходе, чтобы оно было близко к стабилизации при запуске моделирования. Точно так же вы можете указать напряжение в узле компенсации, чтобы исключить начальное падение при запуске.
.ic V (выход) = 11 В (vc) = 1
Уменьшите объем данных анализа переходных процессов
Обычно анализ переходных процессов LTspice начинается в момент времени = 0. Вы можете отредактировать команду симуляции .trans «Время для начала сохранения данных», чтобы отложить сохранение до более позднего интересующего времени, тем самым уменьшив общее время симуляции.Конечно, это предполагает, что вам не нужны исходные точки данных, которые не сохраняются.
В качестве альтернативы, если вас интересуют только напряжения нескольких узлов и токи устройств, вы можете ограничить количество сохраняемых данных с помощью директивы .save, чтобы сохранить только эти конкретные напряжения узлов и токи устройств. В директиве добавьте параметр «диалоговое окно» для отображения всех доступных узлов и токов, чтобы вы могли сохранить дополнительные интересующие данные.
. Сохранить V (выход) I (L1) V (вход) диалоговое окно
Решение для пропуска начальной рабочей точки
Иногда вы замечаете, что моделирование остается в «Анализе псевдопереходных процессов с затуханием» в течение длительного периода времени (информацию о состоянии моделирования см. В нижнем левом углу окна).Обычно это происходит, когда ищется решение постоянного тока, чтобы найти рабочую точку цепи. Если это приемлемо для вашей симуляции, вы можете нажать Esc, чтобы пропустить поиск начальной рабочей точки и продолжить симуляцию. Точно так же вы также можете «Пропустить решение для начальной рабочей точки», отредактировав команду моделирования.
Если вы предпочитаете сохранять трудную для решения рабочую точку постоянного тока, вы можете использовать команду .savebias, чтобы сохранить предпочтительное решение в файл при начальном моделировании, а затем в последующих симуляциях использовать расширение.loadbias, чтобы быстро найти решение постоянного тока перед продолжением остальной части моделирования.
Используйте директиву .savebias в начальном моделировании:
.savebias filename.txt внутреннее время = 10 мин.
Используемые .loadbias в последующих симуляциях:
.loadbias filename.txt
Преобразование в формат быстрого доступа при просмотре сигналов
Для поддержания высокой скорости моделирования LTspice использует сжатый двоичный формат файла, который позволяет быстро добавлять дополнительные данные моделирования на лету.Однако после завершения моделирования этот формат не является оптимальным для просмотра формы сигнала. Чтобы ускорить построение формы сигнала после завершения моделирования, преобразуйте файл в альтернативный формат «Быстрый доступ». Щелкните в окне формы сигнала и выберите «Файлы»> «Преобразовать в быстрый доступ». Это также можно реализовать с помощью директивы fastaccess .option:
. .option fastaccess
Важно отметить, что в некоторых симуляциях это преобразование может занять больше времени, чем реальное моделирование.
Вывод из итеративного моделирования с использованием нескольких последовательностей в JSTOR
Abstract Сэмплер Гиббса, алгоритм Метрополиса и аналогичные методы итеративного моделирования потенциально очень полезны для суммирования многомерных распределений. Однако при наивном использовании итеративное моделирование может дать неверные ответы. Наши методы просты и обычно применимы к выходным данным любого итеративного моделирования; они предназначены для исследователей, в первую очередь интересующихся наукой, лежащей в основе данных и моделей, которые они анализируют, а не для исследователей, интересующихся теорией вероятности, лежащей в основе самих итерационных симуляций.Наша рекомендуемая стратегия - использовать несколько независимых последовательностей, с начальными точками, взятыми из сверхдисперсного распределения. На каждом этапе итеративного моделирования мы получаем для каждой одномерной оценки и представляющую интерес оценку распределения и оценку того, насколько точнее может стать оценка распределения, если моделирование будет продолжаться бесконечно. Поскольку наше внимание сосредоточено на прикладном выводе для байесовских апостериорных распределений в реальных задачах, которые часто имеют тенденцию к нормальности после преобразований и маргинализации, мы получаем наши результаты как приближения нормальной теории к точному байесовскому выводу, обусловленные наблюдаемым моделированием.Методы проиллюстрированы на модели смеси случайных эффектов, применяемой к экспериментальным измерениям времени реакции нормальных пациентов и пациентов с шизофренией.
Информация журнала Цель статистической науки - представить полный спектр
современная статистическая мысль на техническом уровне, доступном широкому кругу лиц.
сообщество практиков, учителей, исследователей и студентов, изучающих статистику
и вероятность. В журнале публикуются обсуждения методологических и теоретических тем.
актуальные и актуальные, обзоры основных областей исследований
с перспективными статистическими приложениями, подробными обзорами книг, обсуждениями
классических статей из статистической литературы и интервью с известными
статистики и вероятностники.
Информация об издателе Целью Института математической статистики (IMS) является содействие
развитие и распространение теории и приложений статистики
и вероятность. Институт сформирован на встрече заинтересованных лиц.
12 сентября 1935 года в Анн-Арборе, штат Мичиган, вследствие чувства
что теория статистики будет продвинута с образованием организации
тех, кто особенно интересуется математическими аспектами предмета.Летопись статистики и Анналы вероятности
(которые заменяют "Анналы математической статистики"), Статистические
Наука и Анналы прикладной вероятности - это научные
журналы института.
